1, Preface framework
I haven't wanted to teach you urlib before. I think a lot. I still need to make up this tutorial.
Let's learn about urlib, the ancestor of the reptile. No matter what module you have, it originates from this module.
The urlib library has several modules, as follows:
- request: module for requesting web address
- error: exception handling module
- parse: module used to modify splicing, etc
- Robot parser: used to determine which websites can be crawled and which websites cannot be crawled
2, URL request
2.1 open website
Take requesting my own blog as an example. My blog link is:
https://blog.csdn.net/weixin_46211269?spm=1000.2115.3001.5343
We use the request module in the urlib library as follows:
import urllib.request
response = urllib.request.urlopen('https://blog.csdn.net/weixin_46211269?spm=1000.2115.3001.5343')
print(response.read().decode('utf-8'))#Call the read method to get the returned web page content and print the web page content
Operation results:
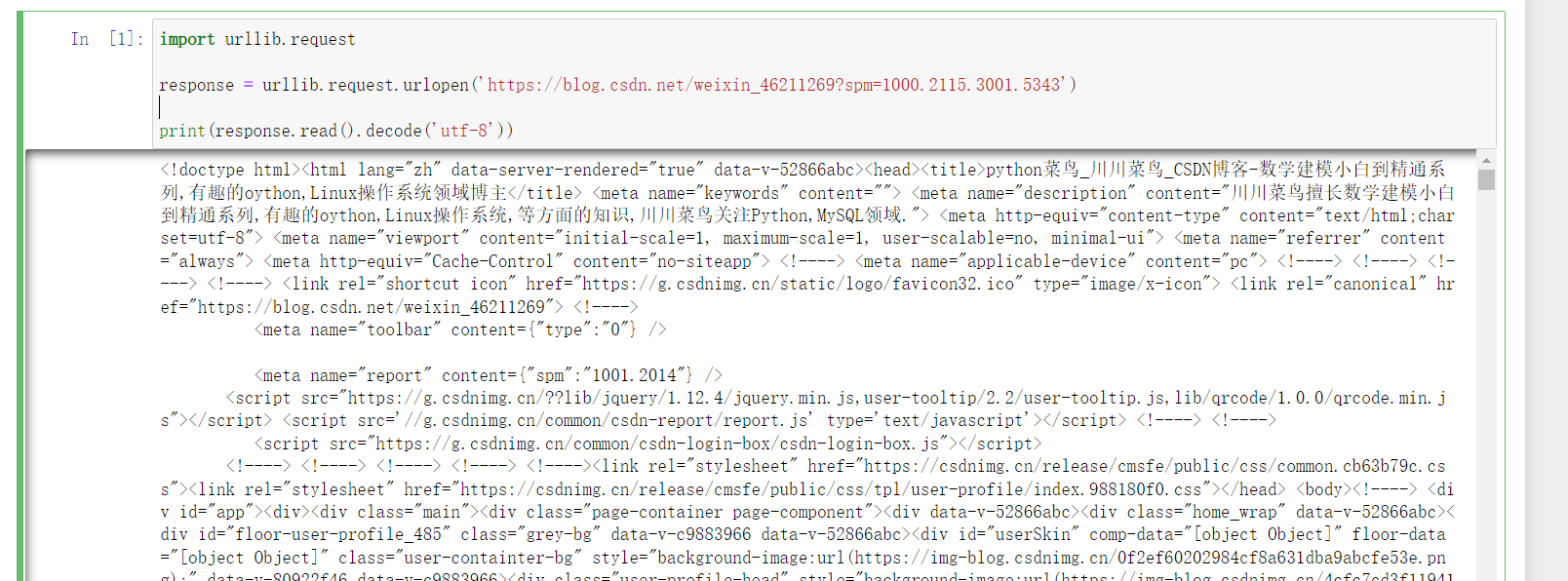
Leave a question: can you ask for another website? Like your own blog?
Let's then look at other questions: how do you know that you have successfully requested a website? I don't want to print him out every time to see if I succeed.
We use the status function to check. This word means status. If the return result is 200, the request is successful, and 404 means the request failed.
Suppose I ask my blog:
import urllib.request
response = urllib.request.urlopen('https://blog.csdn.net/weixin_46211269?spm=1000.2115.3001.5343')
print(response.status)
function:

You can see that it is 200, which means the request is successful. So let's ask for another website? For example, let's ask facebook abroad:
import urllib.request
response = urllib.request.urlopen('https://www.facebook.com/')
print(response.status)
function:

Surprisingly, my request succeeded, but I guess you may ask for 404. It doesn't matter. It's normal.
2.2 timeout setting
We only need to add the timeout parameter. Why should we use the timeout setting? Because we can't request access to some websites immediately, it may be due to our own network or the other party's server jamming. Therefore, we need to set the timeout to not request when it exceeds the specified time.
For example: I want to request to open github for no more than ten seconds. If it exceeds ten seconds, I won't request it.
import urllib.request
response = urllib.request.urlopen('https://github.com/',timeout=10)
print(response.status)
Run to see:

Display time out means timeout opening error. If you change the request from 10 seconds to 30 seconds, try again whether it can succeed? (after all, it's normal for github cards in China)
2.3 error fetching
In the past, we will report a lot of errors when the request times out. If we judge whether the request is successful first, we need to use try... except to obtain the error information, as follows:
import socket
import urllib.request
import urllib.error
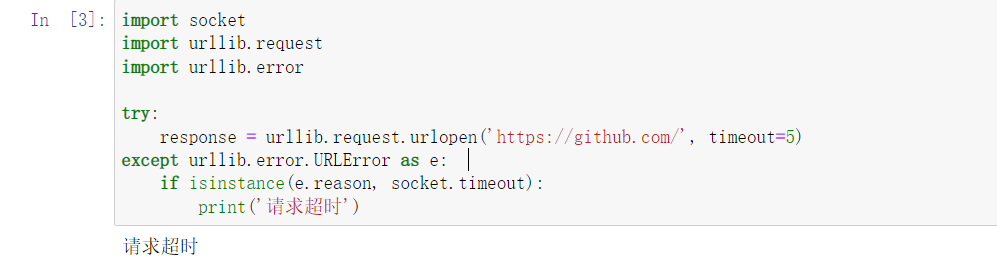
try:
response = urllib.request.urlopen('https://github.com/', timeout=5)
except urllib.error.URLError as e:
if isinstance(e.reason, socket.timeout):
print('request timeout')
Run to see:
3, Deeper request
3.1 open website
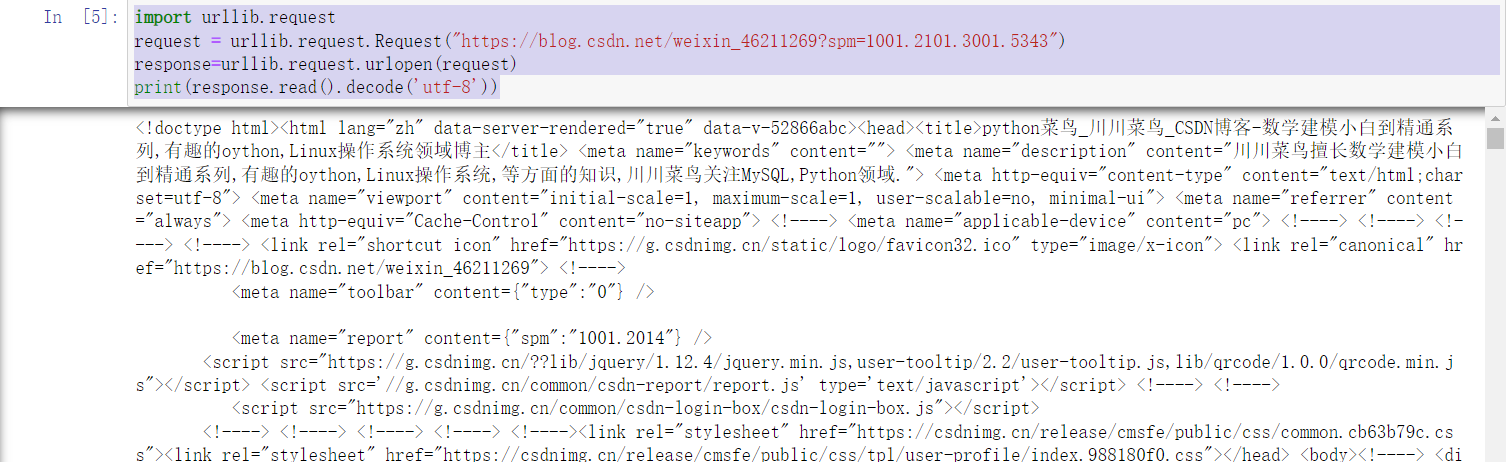
import urllib.request
request = urllib.request.Request("https://www.csdn.net/?spm=1011.2124.3001.5359")
response=urllib.request.urlopen(request)
print(response.read().decode('utf-8'))
Tell me what each line is about.
- First line import module
- The second line Requests the web address with Requests
- The third line opens the URL with urlopen
- The fourth line prints the content with read
Run to see:
3.2 request header addition
Why add a request header? The function of the request header is to simulate the browser to crawl the content, mainly to be stolen.
There is a new word: why is anti pickpocketing anti pickpocketing? Because some websites don't allow you to crawl, but we just need to crawl the content, so we use the request header to simulate. The addition of request header can help us solve 80% of anti pickpocketing. Don't worry about me. I will teach you the anti pickpocketing technology in the back.
For example, we have climbed the CSDN homepage as an example:
from urllib import request
url='https://www.csdn.net/?spm=1011.2124.3001.5359'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36'}
req=request.Request(url=url,headers=headers)
response=request.urlopen(req)
print(response.read().decode('utf-8'))
Some examples of each line:
- The first line imports the module from the library
- The second line is the URL we need to request
- The third line is our request header. Fix this pattern without reciting it. In the future, add the request header and copy and paste it
- The fourth line is to use the request header to request the web address
- Line 5: the request successfully opens the URL
- The sixth line prints the content with read
3.3 link resolution
I directly take the home page of CSDN official website as an example.
1.urlparse
from urllib.parse import urlparse
s=urlparse('https://www.csdn.net/?spm=1011.2124.3001.5359 ') # resolved website
print(type(s),s)#Print type and resolution results
Look at the print results:

Analyze the following results:
ParseResult this type of object prints six partial results:
scheme is the protocol. The protocol here is https
netloc is a domain name. Just say what the domain name is. Baidu itself
Path is the access path
params is the parameter
Query is a query condition, which is generally used as a url of get type
fragment is a tracing point used to locate the drop-down position inside the page
So the standard link format of the website is:
scheme: //netloc/path;params?query#fragment
These can understand what constitutes a web site
2.urlunparse
In contrast to the first, the parameter he accepts is an iteratable object, and the object length must be 6
from urllib.parse import urlunparse data=['http','www.baidu.com','index.com','user','a=7','comment'] print(urlunparse(data))
The results are as follows:

This constructs a url. Of course, it cannot be accessed normally by arbitrarily constructing a url. Compared with the urlparse above, one is to split the url, and this is to construct the url.
3.urlsplit
Similar to urlparse, there are only five returned results of knowledge, and params is merged into the path
from urllib.parse import urlsplit
s=urlsplit('https://www.csdn.net/?spm=1011.2124.3001.5359')
print(type(s),s)
The old rule is to take the CSDN home page as an example to see the print results:

However, SplitResult is a tuple type. You can get what you want by asking for it without printing it all:
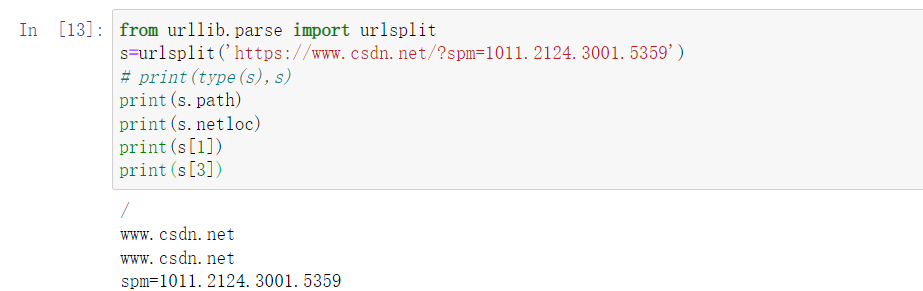
from urllib.parse import urlsplit
s=urlsplit('https://www.csdn.net/?spm=1011.2124.3001.5359')
# print(type(s),s)
print(s.path)
print(s.netloc)
print(s[1])
print(s[3])
The printing results are as follows:
4.urlunsplit()
Similar to the above method, this is to combine all parts into a complete link. The length must be 5. For example:
from urllib.parse import urlunsplit data=['http','www.csdn.net','/','spm=1011.2124.3001.5359',' '] print(urlunsplit(data))
According to the split results printed earlier, I restored it. The running results are as follows, and the csdn home page link is obtained again

5.urljoin
It is the supplement and combination of links. You can print more and try
from urllib.parse import urljoin
print(urljoin('http://www.baidu.com','index.html'))
print(urljoin('http://www.baidu.com','http://www.baidu.com/index.html'))
The effects are as follows:

6.urlencode
Similar to the above, it is also used to construct URLs
Examples are as follows:
from urllib.parse import urlencode
parms={
'name':'chuan',
'age':'20'
}
b_url='http://www.baidu.com?'
url=b_url+urlencode(parms)
print(url)
result:

7.parse_qs
from urllib.parse import parse_qs u='name=chuan&age=20' print(parse_qs(u))
parse_ The function of QS is to convert the obtained get request parameter string into a dictionary, which is easy to understand. There is serialization in the front, which is de disorder.

8.parse_sql
from urllib.parse import parse_qsl u='name=chuan&age=20' print(parse_qsl(u))

Similar to the seventh method above, this is the returned list. The tuples in the list are the name on the left and the value on the right
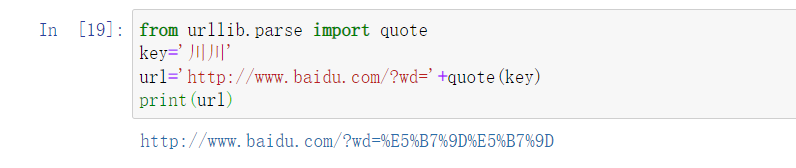
9.quote
from urllib.parse import quote key='Chuan Chuan' url='http://www.baidu.com/?wd='+quote(key) print(url)
This is very common. My understanding is to convert Chinese into url format. Code Chinese.
10.unquote
from urllib.parse import unquote url='http://www.baidu.com/?wd=%E5%B7%9D%E5%B7%9D' print(unquote(url))
It can restore the encoded Chinese.

That's almost all for this module. Take your time learning crawlers. Don't accomplish it overnight. With this module, you can parse and construct the url.
4, Robots protocol
Although I'm teaching you to crawl, I still want to make a statement that we don't climb everything, so let's see what can and can't climb, which should be based on the robots agreement. (of course, we may not fully abide by his agreement, otherwise the reptile will be meaningless and keep its own measure)
First, let's learn how to view the protocol. For example, we need to visit the CSDM website:
https://www.csdn.net/
Check the agreement: add robots.txt after the web address
https://www.csdn.net/robots.txt
Enter enter:
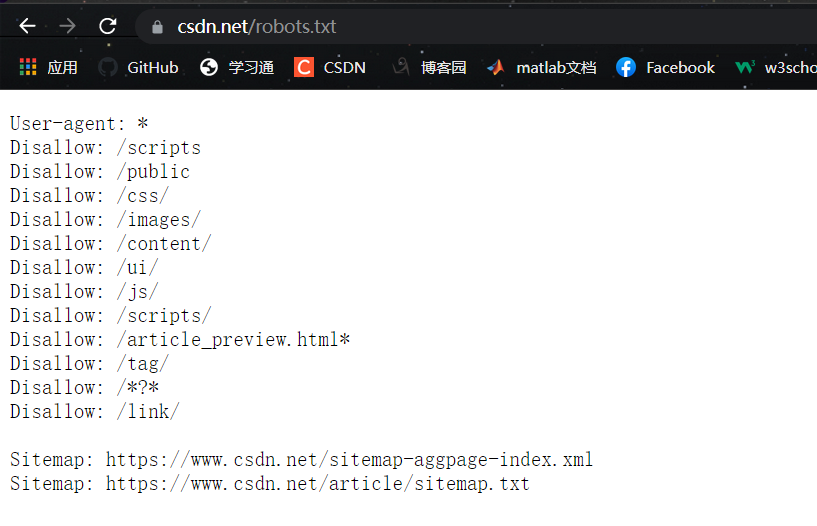
Look at the meaning of this Agreement:
User agent: followed by the name of the spider, which means an agent;
disallowed: indicates forbidden. The following content is forbidden to be grabbed by spiders;
Allowed: indicates that the spider is allowed to grab the contents of the following files;
Good guy, CSDN is not allowed to climb. Hahaha, it's okay. It's OK to climb properly.
5, Universal video download
I won't talk about it. You can download almost 100% of online and platform videos and try it yourself (please use it quietly)
Download the installation package:
pip install you_get
Create a new mp4 folder with the code sibling directory.
The source code is as follows:
import sys
from you_get import common as you_get# Import you get Library
# Set download directory
directory=r'mp4\\'
# Video address to download
url='https://music.163.com/#/mv?id=14306186'
# Fixed transmission parameters
sys.argv=['you-get','-o',directory,'--format=flv',url].encode('utf-8')
you_get.main()
effect:
