This series of articles is an experiment arranged for the computer system, a basic course of computer science at the University of science and technology of China. The teaching materials and contents used in the class are black book CSAPP. At that time, it took a lot of energy and detours. Now let's summarize each experiment. This article is the fourth experiment - performance optimization experiment (Perflab).
1, Experiment Name: perflab
2, Experimental hours: 3
3, Experiment content and purpose:
This experiment optimizes the image processing code. Image processing provides many functions that can be improved by optimization. In this experiment, we will consider two image processing operations: roate, which is used to rotate the image 90 ° counterclockwise; And smooth to "smooth" or "blur" the image.
For this experiment, we will consider that the image is represented by a two-dimensional matrix M , and represented by Mi,j , is used to represent the pixel value of the position (i, j). The pixel value is a triple composed of red, green and blue (RGB). We only consider the square image. N , is used to represent the number of rows (and also the number of columns) of the image. Rows and columns are numbered in C style - from 0 to N - 1.
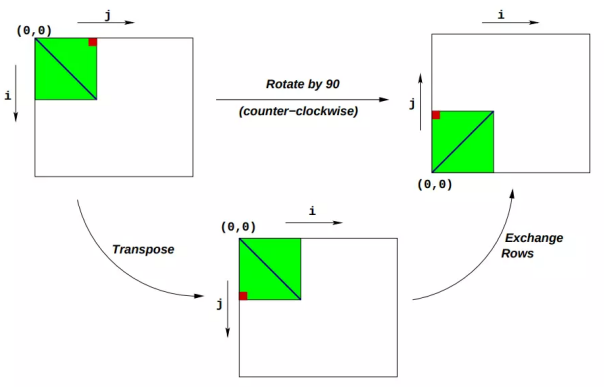
Under this representation method, the rotate} operation can be simply realized by the combination of the following two matrix operations:
- Transpose: for each (I, j), exchange Mi,j , and Mj,i.
- Line exchange: exchange lines i and N - 1 - i.
See the figure below for details:
The smooth operation can be performed by calculating each pixel and the surrounding pixels (up to 3 pixels centered on this pixel) × The mean value of 3. See Figure 2 for details. The pixels M2[1][1] and M2[N - 1][N - 1] are given by the following formula:
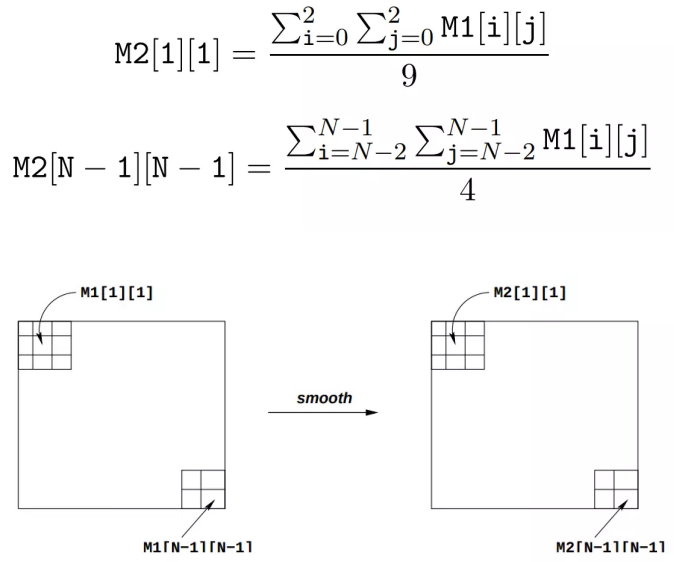
IV. experimental steps and results:
First, set perflab - handle Tar is copied to a protected folder to complete the experiment.
Then, on the command line, enter the command: tar xvf perflab - handle Tar this will cause several files to be extracted to the current directory.
The only file you can modify and eventually submit is kernels C program driver C is a driver that you can use to evaluate the performance of your solution. Use the command: make driver to generate driver code and use the command/ Driver to make it run.
View the file kernels c. You will find a C structure: team. You need to fill in the information of your team members. Please fill it out immediately in case you forget.
1.naive_rotate
/*
*naive_rotate - The naive baseline version of rotate
*/
char naive_rotate_descr[] ="naive_rotate: Naive baseline implementation";
void naive_rotate(int dim, pixel *src,pixel *dst)
{
int i, j;
for (i = 0; i < dim; i++)
for(j = 0; j < dim; j++)
dst[RIDX(dim-1-j, i, dim)] = src[RIDX(i, j,dim)];
}In the header file defs Macro definition found in H:
#defineRIDX(i,j,n) ((i)*(n)+(j))
Then this code is easy to rotate a picture. It will adjust all pixels in rows and columns, resulting in a 90 degree rotation of the whole picture.
However, because the step size of this string of code is too long, the cache hit rate is very low, so the overall operation efficiency is low. Therefore, considering the size of the cache, we should store 32 pixels in sequence (column storage) during storage. (32 pixels are arranged to make full use of the first level cache (32KB). The blocking strategy is adopted, and the size of each block is 32)
This can be cache friendly and greatly improve efficiency.
2.perf_rotate
Consider the rectangular block 32 * 1, 32 loop expansion, and make the dest address continuous to reduce the number of memory writes
//Macro defines a copy function to facilitate programming
#define COPY(d,s) *(d)=*(s)
char rotate_descr[] = "rotate: Currentworking version";
void rotate( int dim,pixel *src,pixel *dst)
{
int i,j;
for(i=0;i<dim;i+=32)//32 channels of cyclic expansion and 32 pixels are stored in turn
for(j=dim-1;j>=0;j-=1)
{
pixel*dptr=dst+RIDX(dim-1-j,i,dim);
pixel*sptr=src+RIDX(i,j,dim);
//Copy operation
COPY(dptr,sptr);sptr+=dim;
COPY(dptr+1,sptr);sptr+=dim;
COPY(dptr+2,sptr);sptr+=dim;
COPY(dptr+3,sptr);sptr+=dim;
COPY(dptr+4,sptr);sptr+=dim;
COPY(dptr+5,sptr);sptr+=dim;
COPY(dptr+6,sptr);sptr+=dim;
COPY(dptr+7,sptr);sptr+=dim;
COPY(dptr+8,sptr);sptr+=dim;
COPY(dptr+9,sptr);sptr+=dim;
COPY(dptr+10,sptr);sptr+=dim;
COPY(dptr+11,sptr);sptr+=dim;
COPY(dptr+12,sptr);sptr+=dim;
COPY(dptr+13,sptr);sptr+=dim;
COPY(dptr+14,sptr);sptr+=dim;
COPY(dptr+15,sptr);sptr+=dim;
COPY(dptr+16,sptr);sptr+=dim;
COPY(dptr+17,sptr);sptr+=dim;
COPY(dptr+18,sptr);sptr+=dim;
COPY(dptr+19,sptr);sptr+=dim;
COPY(dptr+20,sptr);sptr+=dim;
COPY(dptr+21,sptr);sptr+=dim;
COPY(dptr+22,sptr);sptr+=dim;
COPY(dptr+23,sptr);sptr+=dim;
COPY(dptr+24,sptr);sptr+=dim;
COPY(dptr+25,sptr);sptr+=dim;
COPY(dptr+26,sptr);sptr+=dim;
COPY(dptr+27,sptr);sptr+=dim;
COPY(dptr+28,sptr);sptr+=dim;
COPY(dptr+29,sptr);sptr+=dim;
COPY(dptr+30,sptr);sptr+=dim;
COPY(dptr+31,sptr);
}
}3.smooth
char naive_smooth_descr[] ="naive_smooth: Naive baseline implementation";
void naive_smooth(int dim, pixel *src,pixel *dst)
{
int i, j;
for (i = 0; i < dim; i++)
for (j = 0; j < dim; j++)
dst[RIDX(i, j, dim)] = avg(dim, i, j, src);
}This code calls the avg function frequently, and initialize is also called frequently in the avg function_ pixel_ sum ,accumulate_sum,assign_sum_to_pixel functions also contain two-tier for loops, and we should reduce the time overhead of function calls. Therefore, you need to rewrite the code without calling the avg function.
Special circumstances, special treatment:
Smooth function processing is divided into four parts. One is the internal part of the main body, and the average value is calculated from 9 points; The second is 4 vertices, and the average value is obtained from 4 points; Three are four boundaries, and the average value is obtained from 6 points. Start processing from the top of the picture, then the upper boundary, and process it in sequence. When processing the left boundary, the for loop processes the main part of a line, so there is the following optimized code.
4.perf_smooth
charsmooth_descr[] = "smooth: Current working version";
void smooth(intdim, pixel *src, pixel *dst) {
int i,j;
int dim0=dim;
int dim1=dim-1;
int dim2=dim-2;
pixel *P1, *P2, *P3;
pixel *dst1;
P1=src;
P2=P1+dim0;
//The upper left pixel processing uses shift operation instead of some operations of avg
dst->red=(P1->red+(P1+1)->red+P2->red+(P2+1)->red)>>2; dst->green=(P1->green+(P1+1)->green+P2->green+(P2+1)->green)>>2; dst->blue=(P1->blue+(P1+1)->blue+P2->blue+(P2+1)->blue)>>2;
dst++;
//Upper boundary treatment
for(i=1;i<dim1;i++) {
dst->red=(P1->red+(P1+1)->red+(P1+2)->red+P2->red+(P2+1)->red+(P2+2)->red)/6; dst->green=(P1->green+(P1+1)->green+(P1+2)->green+P2->green+(P2+1)->green+(P2+2)->green)/6; dst->blue=(P1->blue+(P1+1)->blue+(P1+2)->blue+P2->blue+(P2+1)->blue+(P2+2)->blue)/6;
dst++;
P1++;
P2++;
}
//Upper right corner pixel processing DST - > red = (P1 - > Red + (P1 + 1) - > Red + P2 - > Red + (P2 + 1) - > Red) > > 2;
dst->green=(P1->green+(P1+1)->green+P2->green+(P2+1)->green)>>2; dst->blue=(P1->blue+(P1+1)->blue+P2->blue+(P2+1)->blue)>>2;
dst++;
P1=src;
P2=P1+dim0;
P3=P2+dim0;
//Left boundary processing
for(i=1;i<dim1;i++) {
dst->red=(P1->red+(P1+1)->red+P2->red+(P2+1)->red+P3->red+(P3+1)->red)/6; dst->green=(P1->green+(P1+1)->green+P2->green+(P2+1)->green+P3->green+(P3+1)->green)/6; dst->blue=(P1->blue+(P1+1)->blue+P2->blue+(P2+1)->blue+P3->blue+(P3+1)->blue)/6;
dst++;
dst1=dst+1;
}
//Main body middle part processing
for(j=1;j<dim2;j+=2) {
//Simultaneous processing of 2 pixels
dst->red=(P1->red+(P1+1)->red+(P1+2)->red+P2->red+(P2+1)->red+(P2+2)->red+P3->red+(P3+1)->red+(P3+2)->red)/9;
dst->green=(P1->green+(P1+1)->green+(P1+2)->green+P2->green+(P2+1)->green+(P2+2)->green+P3->green+(P3+1)->green+(P3+2)->green)/9;
dst->blue=(P1->blue+(P1+1)->blue+(P1+2)->blue+P2->blue+(P2+1)->blue+(P2+2)->blue+P3->blue+(P3+1)->blue+(P3+2)->blue)/9;
dst1->red=((P1+3)->red+(P1+1)->red+(P1+2)->red+(P2+3)->red+(P2+1)->red+(P2+2)->red+(P3+3)->red+(P3+1)->red+(P3+2)->red)/9;
dst1->green=((P1+3)->green+(P1+1)->green+(P1+2)->green+(P2+3)->green+(P2+1)->green+(P2+2)->green+(P3+3)->green+(P3+1)->green+(P3+2)->green)/9;
dst1->blue=((P1+3)->blue+(P1+1)->blue+(P1+2)->blue+(P2+3)->blue+(P2+1)->blue+(P2+2)->blue+(P3+3)->blue+(P3+1)->blue+(P3+2)->blue)/9;
dst+=2;dst1+=2;P1+=2;P2+=2;P3+=2;
}
for(;j<dim1;j++) {
dst->red=(P1->red+(P1+1)->red+(P1+2)->red+P2->red+(P2+1)->red+(P2+2)->red+P3->red+(P3+1)->red+(P3+2)->red)/9;
dst->green=(P1->green+(P1+1)->green+(P1+2)->green+P2->green+(P2+1)->green+(P2+2)->green+P3->green+(P3+1)->green+(P3+2)->green)/9;
dst->blue=(P1->blue+(P1+1)->blue+(P1+2)->blue+P2->blue+(P2+1)->blue+(P2+2)->blue+P3->blue+(P3+1)->blue+(P3+2)->blue)/9;
dst++; P1++;P2++;P3++;
}
//Right side boundary processing DST - > red = (P1 - > Red + (P1 + 1) - > Red + P2 - > Red + (P2 + 1) - > Red + P3 - > Red + (P3 + 1) - > Red) / 6; dst->green=(P1->green+(P1+1)->green+P2->green+(P2+1)->green+P3->green+(P3+1)->green)/6; dst->blue=(P1->blue+(P1+1)->blue+P2->blue+(P2+1)->blue+P3->blue+(P3+1)->blue)/6;
dst++; P1+=2; P2+=2; P3+=2;
}
//Lower left corner processing DST - > red = (P1 - > Red + (P1 + 1) - > Red + P2 - > Red + (P2 + 1) - > Red) > > 2;
dst->green=(P1->green+(P1+1)->green+P2->green+(P2+1)->green)>>2;
dst->blue=(P1->blue+(P1+1)->blue+P2->blue+(P2+1)->blue)>>2;
dst++;
//Lower boundary treatment
for(i=1;i<dim1;i++) {
dst->red=(P1->red+(P1+1)->red+(P1+2)->red+P2->red+(P2+1)->red+(P2+2)->red)/6; dst->green=(P1->green+(P1+1)->green+(P1+2)->green+P2->green+(P2+1)->green+(P2+2)->green)/6; dst->blue=(P1->blue+(P1+1)->blue+(P1+2)->blue+P2->blue+(P2+1)->blue+(P2+2)->blue)/6;
dst++; P1++; P2++;
}
//Lower right corner pixel processing DST - > red = (P1 - > Red + (P1 + 1) - > Red + P2 - > Red + (P2 + 1) - > Red) > > 2; dst->green=(P1->green+(P1+1)->green+P2->green+(P2+1)->green)>>2; dst->blue=(P1->blue+(P1+1)->blue+P2->blue+(P2+1)->blue)>>2;
//All processed
}