background
As we all know, one of the core functions of the operating system is task scheduling. By switching a CPU core between multiple executable tasks, the task scheduler can realize that multiple tasks share one or more CPU cores, so as to maximize the use of CPU core resources. At the same time, through fast task switching, users can feel that tasks larger than the number of CPU cores are executed at the same time to realize concurrent operation.
Generally speaking, common task scheduling algorithms include FCFS, SJF, RR, priority scheduling, multilevel queue and multilevel feedback queue. Many operating system books have detailed descriptions of these algorithms, which will not be introduced in detail here.
Will the task scheduler use a separate thread
Does the operating system task scheduler need a separate thread? The answer is yes or no. In this chapter, xv6 operating system and linux operating system used in the teaching of MIT Operating System Engineering course are used as examples to illustrate the two implementation schemes.
xv6
xv6 runs on a multi-core RISC-V processor simulated by qemu. qemu also simulates UART 16550 chip, CLINT, and disk image to realize basic I / O, time interrupt and file system functions.
The detailed code of xv6 can be obtained through git:
git clone git://github.com/mit-pdos/xv6-riscv.git
When xv6 starts, all RISC-V cores will execute kernel code from 0x8000000. After a series of operating system initialization, all cores will enter their own thread scheduler. The scheduler function is scheduler():
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
c->proc = 0;
for(;;){
// Avoid deadlock by ensuring that devices can interrupt.
intr_on();
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
if(p->state == RUNNABLE) {
// Switch to chosen process. It is the process's job
// to release its lock and then reacquire it
// before jumping back to us.
p->state = RUNNING;
c->proc = p;
swtch(&c->context, &p->context);
// Process is done running for now.
// It should have changed its p->state before coming back.
c->proc = 0;
}
release(&p->lock);
}
}
}
Since each CPU core has its own stack area in the initialization phase, the scheduler of each core is executed in a separate thread.
The scheduler() will select a process in RUNNABLE status from the process array, and then switch the context to this process by calling swtch().
When a time interrupt occurs, the interrupt handler will call yield(). yield() first changes the state of the process from RUNNING to RUNNING, and then calls swtch through sched() to switch the context to the scheduling thread of the current CPU core. The scheduling thread completes the task switching in the above way.
void
yield(void)
{
struct proc *p = myproc();
acquire(&p->lock);
p->state = RUNNABLE;
sched();
release(&p->lock);
}
void
sched(void)
{
int intena;
struct proc *p = myproc();
if(!holding(&p->lock))
panic("sched p->lock");
if(mycpu()->noff != 1)
panic("sched locks");
if(p->state == RUNNING)
panic("sched running");
if(intr_get())
panic("sched interruptible");
intena = mycpu()->intena;
swtch(&p->context, &mycpu()->context);
mycpu()->intena = intena;
}
The process will also voluntarily give up CPU resources and enter the sleep state. At this time, sleep() changes the process state from RUNNING to SLEEPING, and then calls swtch through sched() to switch the context to the scheduling thread of the current CPU core, and the scheduling thread completes the task switching.
void
sleep(void *chan, struct spinlock *lk)
{
struct proc *p = myproc();
// Must acquire p->lock in order to
// change p->state and then call sched.
// Once we hold p->lock, we can be
// guaranteed that we won't miss any wakeup
// (wakeup locks p->lock),
// so it's okay to release lk.
acquire(&p->lock); //DOC: sleeplock1
release(lk);
// Go to sleep.
p->chan = chan;
p->state = SLEEPING;
sched();
// Tidy up.
p->chan = 0;
// Reacquire original lock.
release(&p->lock);
acquire(lk);
}
It can be seen that xv6 puts the scheduler in a separate thread. When the system needs to switch tasks, it needs to switch the current task to the scheduler thread, and the scheduler thread switches to other tasks according to the scheduling algorithm.
xv6 puts the scheduler in a special thread. The main consideration is to use a simple method to avoid multiple CPU cores executing tasks in the same RUNNABLE state at the same time, resulting in stack usage interference:
As shown in the figure below, when a time interrupt occurs, the current task calls yield() to change the task status from RUNNING to unavailable, and then switch tasks through swtch(); The state of each task is protected by a spin lock, which can only be released when swtch() completes task switching. Otherwise, during task switching, another CPU core may execute the current task, causing confusion. After xv6 switches the current task to the task scheduling thread, the first thing for scheduler() is to release the state protection spin lock of the previous task, and the previous task can be executed by other CPU cores. The task scheduling thread of the current CPU core can switch to other RUNNABLE tasks according to the task scheduling algorithm.
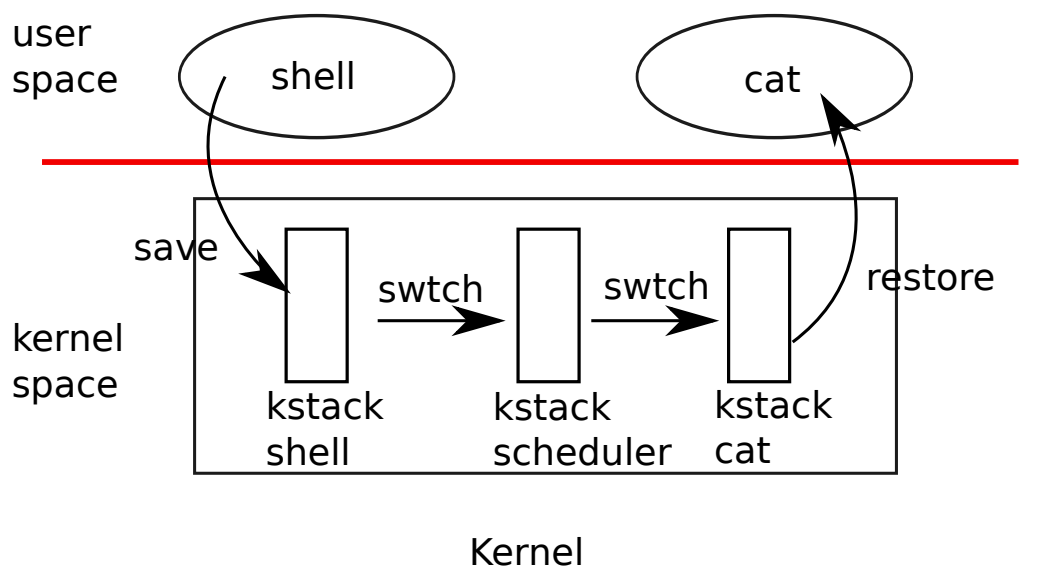
If the task scheduler is not in a special thread, xv6 needs to change the state of the previous task in the next task and release the task state protection spin lock, resulting in the complexity of the kernel design.
The disadvantage of putting the task scheduler in a special thread is that it increases the overhead of task switching. It needs to switch one process to another twice each time. However, because xv6 is only a relatively simple operating system for teaching, the cost of task switching is very small, so the two task switching has little impact on the system performance.
Linux
The linux kernel code can be downloaded from the official website: http://www.kernel.org
The linux kernel startup process is much more complex than xv6, so I won't describe it in detail here. This chapter mainly describes whether the linux task scheduler is implemented by special threads.
< unfinished to be continued >