Introduction: at present, the performance of mobile phone SOC is less and less. Many programmers do not pay much attention to performance optimization in the development of terminal programs, especially alignment and branch optimization. However, once these two problems occur, they are very hidden and difficult to check, However, fortunately, with the support of the performance troubleshooting artifact Youmeng U-APM tool used in the project, several problems were successfully solved in the end.
Let's first look at the problem of alignment. Alignment will not have any problems without concurrent competition. Compilers generally help programmers align according to CPU word length, but this may hide huge performance problems when terminal multithreads work at the same time. In the case of multithreading concurrency, even if there are no shared variables, it may cause pseudo sharing, Since the specific code is classified, let's look at the following abstract code.
public class Main {
public static void main(String[] args) {
final MyData data = new MyData();
new Thread(new Runnable() {
public void run() {
data.add(0);
}
}).start();
new Thread(new Runnable() {
public void run() {
data.add(0);
}
}).start();
try{
Thread.sleep(100);
} catch (InterruptedException e){
e.printStackTrace();
}
long[][] arr=data.Getitem();
System.out.println("arr0 is "+arr[0]+"arr1 is"+arr[1]);
}
}
class MyData {
private long[] arr={0,0};
public long[] Getitem(){
return arr;
}
public void add(int j){
for (;true;){
arr[j]++;
}
}
}
In this code, the two sub threads perform similar tasks and operate two members of the ARR array respectively. Since the operation objects of the two sub threads are arr[0] and arr[1], there is no cross problem, it was judged that there will be no concurrent competition, and the synchronized keyword was not added.
However, this program often gets stuck inexplicably. Later, after searching in many ways, and finally through the Caton analysis function of Youmeng, we finally locate the above code segment and find that this is a problem caused by not aligning according to the cache line. Here, we will explain the modified pseudo code to you first:
public class Main {
public static void main(String[] args) {
final MyData data = new MyData();
new Thread(new Runnable() {
public void run() {
data.add(0);
}
}).start();
new Thread(new Runnable() {
public void run() {
data.add(0);
}
}).start();
try{
Thread.sleep(10);
} catch (InterruptedException e){
e.printStackTrace();
}
long[][] arr=data.Getitem();
System.out.println("arr0 is "+arr[0][0]+"arr1 is"+arr[1][0]);
}
}
class MyData {
private long[][] arr={{0,0,0,0,0,0,0,0,0},{0,0}};
public long[][] Getitem(){
return arr;
}
public void add(int j){
for (;true;){
arr[j][0]++;
}
}
}
It can be seen that the overall program has not changed, but the original array has been changed into a two-dimensional array. Except for the arr0 element in the first array, the other arr0-a0 elements do not play any role related to program operation at all. However, such a small change has brought about a significant improvement in performance of nearly 20%, If there is more concurrency, the increase will be more obvious.
Cache line alignment troubleshooting analysis process
First, we changed the multithreading of the previous code to single thread serial execution, and found that the efficiency was not much worse than that of the original code, which basically determined that this was a problem caused by pseudo sharing, but there was no variable sharing problem in my initial code, so it can be judged that it was caused by alignment.
Modern CPUs generally do not access memory by bit, but by word length. When the CPU loads read variables into registers from memory or disk, the minimum unit of each operation generally depends on the word length of the CPU. For example, if the 8-bit word is 1 byte, at least 1 byte, that is, 8-bit long data, is loaded from the memory. For example, the 32-bit CPU loads at least 4 bytes of data each time, the 64 bit system 8 bytes, and so on. Then take the 8-bit computer as an example, let's take a look at this problem. If variable 1 is a variable of bool type, which occupies 1 bit space, and variable 2 is a byte type, which occupies 8 bits space. If the program currently wants to access variable 2, the CPU will read 8 bits from the starting 0x00 position for the first time, that is, all the upper 7 bits of bool type variable 1 and byte type variable 2 are read into memory, but the lowest bit of byte variable is not read in, A second read is required to read the complete variable 2.
In other words, the storage of variables should be aligned according to the word length of the CPU. When the length of the accessed variable is less than an integer multiple of the word length of the CPU, the length of the variable needs to be supplemented. This can improve the access efficiency between CPU and memory and avoid additional memory reading operations. However, most compilers do well in alignment. By default, the C compiler allocates spatial boundaries for each variable or data unit according to its natural boundary conditions. You can also change the default alignment condition instruction by calling pragma pack(n). After calling, the C compiler will align n bytes according to the N specified in pack(n), which actually corresponds to. Align in assembly language. So why is there a pseudo shared alignment problem?
In modern CPUs, in addition to word length alignment, cache line alignment is also required to avoid the competition in the concurrent environment. At present, the cache line size of the mainstream ARM core mobile SOC is 64byte, because each CPU is equipped with its own exclusive level-1 cache. The level-1 cache is basically the speed of the register. Each memory access CPU not only reads the memory address to be accessed, The data before and after 64bytes will also be read into the cache. If the two variables are placed in the same cache line, even if different CPU cores operate the two independent variables respectively, in the actual scenario, the CPU core is actually operating the same cache line, which is also the reason for this performance problem.
Switch pit
However, after dealing with this alignment problem, although our program performs well in most cases, it will still get stuck. It is found that this is a problem caused by the Switch branch.
switch is a branch processing structure that we often use when programming in java, c and other languages. Its main function is to judge the value of variables and send the program code to different branches. This design was very exquisite in the environment at that time, but running in the latest mobile SOC environment will bring many unexpected pitfalls.
For the same reasons as before, the real code cannot be disclosed. Let's take a look at the following code first:
public class Main {
public static void main(String[] args) {
long now=System.currentTimeMillis();
int max=100,min=0;
long a=0;
long b=0;
long c=0;
for(int j=0;j<10000000;j++){
int ran=(int)(Math.random()*(max-min)+min);
switch(ran){
case 0:
a++;
break;
case 1:
a++;
break;
default:
c++;
}
}
long diff=System.currentTimeMillis()-now;
System.out.println("a is "+a+"b is "+b+"c is "+c);
}
}
The random number is actually the return of an rpc remote call, but this code is always inexplicably stuck. In order to reproduce this stuck, locating this code segment is also found through the stuck analysis of Youmeng U-APM. To reproduce this stuck, we only need to slightly adjust the max range from 5.
public class Main {
public static void main(String[] args) {
long now=System.currentTimeMillis();
int max=5,min=0;
long a=0;
long b=0;
long c=0;
for(int j=0;j<10000000;j++){
int ran=(int)(Math.random()*(max-min)+min);
switch(ran){
case 0:
a++;
break;
case 1:
a++;
break;
default:
c++;
}
}
long diff=System.currentTimeMillis()-now;
System.out.println("a is "+a+"b is "+b+"c is "+c);
}
}
Then the running time will decrease by 30%. However, from our analysis, on average, 97% of the concepts of each random number in code 1 can jump to the final branch only after two judgments. The overall execution expectation of the judgment statement is 20.97 + 10.03, which is about 2, while 30% of the concepts in code 2 can jump to the final branch only after one judgment, The overall judgment execution expectation is 0.31 + 0.62 = 1.5, but code 2 is 30% slower than code 1. In other words, the code logic has not changed at all, but the probability density of the return value range is adjusted, which will greatly reduce the operation efficiency of the program. To explain this problem, we should start with the instruction pipeline.
Instruction pipeline principle
We know that every action of the CPU needs to be triggered by crystal oscillation. Take the ADD instruction as an example. To complete this execution instruction, we need several steps, such as fetching, decoding, fetching operands, executing and fetching operation results, and each step needs a crystal oscillation to push forward, Therefore, before the emergence of pipelining technology, it takes at least 5 to 6 crystal oscillation cycles to execute an instruction.
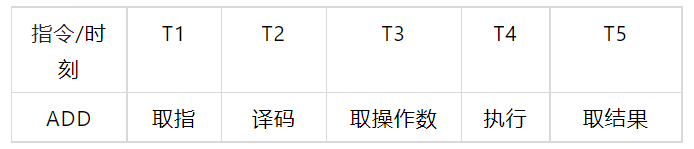
In order to shorten the crystal oscillation cycle of instruction execution, the chip designer referred to the factory pipeline mechanism and put forward the idea of instruction pipeline. Since the modules of finger fetching and decoding are actually independent in the chip and can be executed concurrently at the same time, as long as the different steps of multiple instructions are executed at the same time, such as instruction 1 finger fetching, Instruction 2 decoding, instruction 3 fetching operands, etc. can greatly improve the CPU execution efficiency: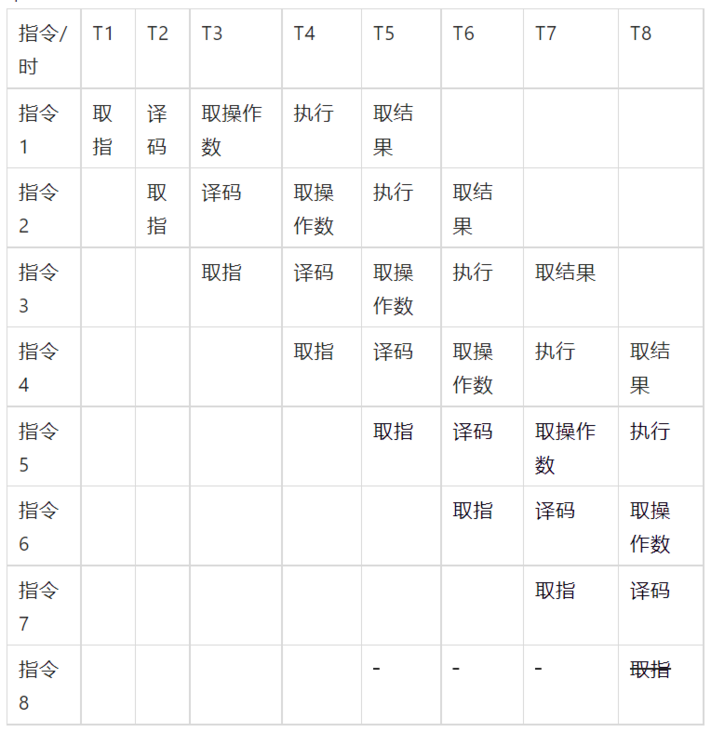
Taking the pipeline in the above figure as an example, before T5, the instruction pipeline is continuously established at the speed of one per cycle. After T5, each oscillation cycle can have an instruction to take the result. On average, each instruction only needs one oscillation cycle to complete. This pipeline design greatly improves the operation speed of the CPU.
However, the CPU pipeline is highly dependent on instruction prediction technology. If instruction 5 should not be executed on the pipeline, but it is found that the prediction fails when the result of instruction 1 has been obtained at T6, instruction 5 will become an invalid bubble on the pipeline. If all instructions 6 to 8 are strongly related to instruction 5 and fail together, Then the whole pipeline needs to be rebuilt.
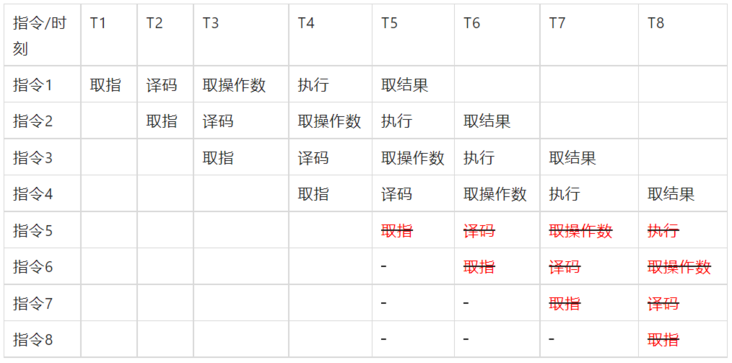
Therefore, it can be seen that the efficiency difference in the example is entirely caused by CPU instruction prediction, that is, the CPU's own mechanism will give more prediction tilt for branches with high execution probability.
Processing suggestions - replace switch with hash table
We also introduced the hash table, that is, the dictionary, which can quickly convert the key value into the value value. To some extent, it can replace the role of switch. According to the logic of the first code, the scheme of rewriting with the hash table is as follows:
import java.util.HashMap;
public class Main {
public static void main(String[] args) {
long now=System.currentTimeMillis();
int max=6,min=0;
HashMap<Integer,Integer> hMap = new HashMap<Integer,Integer>();
hMap.put(0,0);
hMap.put(1,0);
hMap.put(2,0);
hMap.put(3,0);
hMap.put(4,0);
hMap.put(5,0);
for(int j=0;j<10000000;j++){
int ran=(int)(Math.random()*(max-min)+min);
int value = hMap.get(ran)+1;
hMap.replace(ran,value);
}
long diff=System.currentTimeMillis()-now;
System.out.println(hMap);
System.out.println("time is "+ diff);
}
}Although the above code using hash table is not as fast as code 1, it is generally very stable, even if code 2 occurs.
summarize experience
1, For concurrent terminal programming, you must pay attention to the alignment according to the cache line (64byte). If the code is not aligned according to the cache line, the performance will be lost by 20% for each additional thread.
2, Focus on switch and if else branches. Once the value conditions of conditional branches change, the hash table structure should be selected first to optimize the conditional branches.
3, Choose an easy-to-use performance monitoring tool, such as Youmeng U-APM, which is not only free, but also has a comprehensive capture type. It is recommended that you use it.
Original link
This article is the original content of Alibaba cloud and cannot be reproduced without permission.