Introduction: Summarize the basic network structure of AlexNet. Because the computing power required in the implementation of this network is relatively large. Again, it was not tested.
Key words: AlexNet, Paddle
§01 AlexNet
1.1 INTRODUCTION
AlexNet was designed by Hinton, the winner of the 2012 ImageNet competition, and his student Alex Krizhevsky, so it is called AlexNet.
compared with LeNext, AlexNet adds more learning methods for deep CNN networks. The reason why these methods can be implemented depends on:
(1) data, a depth model containing many features, which requires a large number of labeled data to perform better than other classical methods;
(2) hardware (computing power). Deep learning requires high computing resources, but the early hardware computing power is very limited.
until 2012, these two points have been greatly improved, which has led to the birth of the AlexNet model. It proves for the first time that the learned features can surpass the features of manual design, and breaks the bottleneck perplexing the research of computer vision.
- Reference link: Alex net learning
- Original text of the paper: ImageNet Classification with Deep ConvolutionalNeural Networks
1.2 network structure
the design concepts of AlexNet and LeNet are very similar, but there are also very obvious differences:
- First: AlexNet includes 5 layers of convolution, 2 layers of fully connected hidden layer and 1 layer of fully connected output layer;
- Second: the Alex net model changes the sigmoid activation function to a simpler ReLU activation function;
- Thirdly, AlexNet effectively controls the model complexity of the full connection layer by dropping out to prevent the introduction of too many parameters;
- Fourth: AlexNet introduces a large number of image widening, such as flipping, clipping and color change, which effectively increases the number of data samples, so as to alleviate the occurrence of over fitting phenomenon.
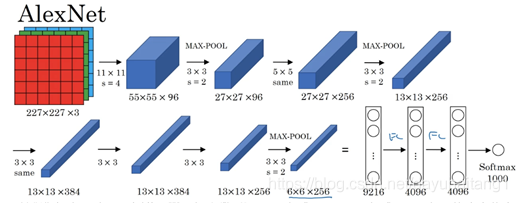
since the image in the ImageNet dataset is much larger than that in the MINST dataset, a larger convolution kernel is required to capture objects. Therefore:
- The window of the first convolution kernel is 11 × eleven
- The second convolution kernel is reduced to 5 × 5. Since then, 3 has been adopted × 3.
- In addition, the window shape of 3 is used after the first, second and fifth convolution layers × 3. The maximum pool layer with a step of 2.
- The last is the general full connection layer.
use the pictures in the book to show it
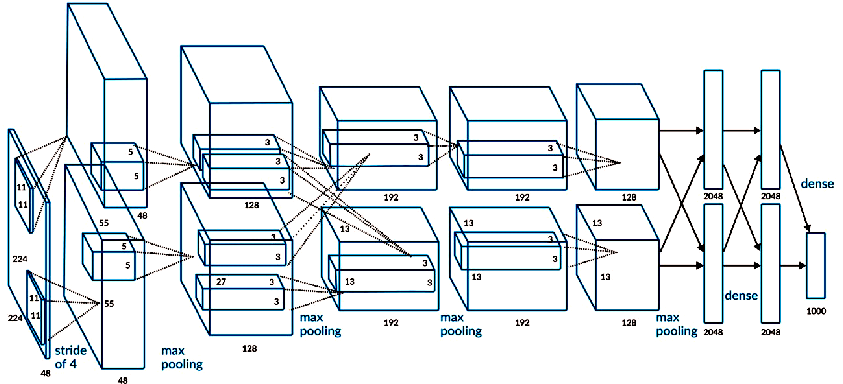
Enter image size:(batch_size,3,224,224) First layer convolution: (96,3,11,11) , padding = 2,stride = 4 Output size:(batch_size,96,55,55) ReLU(), Local Response Normalization max pooling(3,stride = 2) Output size:(batch_size,96,27,27) Second layer convolution: (256,96,5,5) padding = 2,stride = 1 Output size:(batch_size,256,27,27) ReLU(), Local Response Normalization max pooling(3,stride = 2) Output size:(batch_size,256,13,13) Third layer convolution: (384,256,3,3) padding = 1,stride = 1 Output size:(batch_size,384,13,13) ReLU() Fourth layer convolution: (384,384,3,3) padding = 1,stride = 1 Output size:(batch_size,384,13,13) ReLU() Fifth layer convolution: (256,384,3,3) padding = 1,stride = 1 Output size:(batch_size,256,13,13) ReLU() max pooling(3,stride = 2) Output size:(batch_size,256,6,6) sixth/seven/Eighth floor full connection floor (256*6*6,4096) ReLU() Dropout() Output size:(batch_size,4096) (4096,4096) ReLU() Dropout() Output size:(batch_size,4096) (4096,1000) Output size:(batch_size,1000)
in the original paper, two GPU s are used for interaction, so there are two branches in the figure. The AlexNet architecture has 60 million parameters and 650000 neurons, including five layers of convolutional networks, some of which contain max pooling, and three layers of fully connected layers. The number of nodes in the last layer is 1000, which is classified by softmax
but if you are more careful, you will find that 224 of the first convolution layer × 224 is a problem. It should be 227 × 227. This is also mentioned in teacher Wu Enda's video, so the correct figure should be the following one.
1.3 code implementation
the following code comes from: Implementing AlexNet with padding , recorded here for later analysis and utilization.
# -*- coding: utf-8 -*-
# @Time : 2020/1/21 11:18
# @Author : Zhao HL
# @File : alexnet-paddle.py
import os, sys
from PIL import Image
import numpy as np
import pandas as pd
import paddle
from paddle import fluid
from paddle.fluid.layers import data, conv2d, pool2d, flatten, fc, cross_entropy, accuracy, mean
from my_utils import process_show, draw_loss_acc
# region parameters
# region paths
Data_path = "./data/my_imagenet"
Data_csv_path = "./data/my_imagenet.csv"
Model_path = 'model/'
Model_file_tf = "model/alexnet_tf.ckpt"
Model_file_keras = "model/alexnet_keras.h5"
Model_file_torch = "model/alexnet_torch.pth"
Model_file_paddle = "model/alexnet_paddle.model"
# endregion
# region image parameter
Img_size = 227
Img_chs = 3
Label_size = 1
Label_class = {'n02091244': 'Ibizan hound',
'n02114548': 'white wolf',
'n02138441': 'meerkat',
'n03584254': 'iPod',
'n03075370': 'combination lock',
'n09256479': 'coral reef',
'n03980874': 'poncho',
'n02174001': 'rhinoceros beetle',
'n03770439': 'miniskirt',
'n03773504': 'missile'}
Labels_nums = len(Label_class)
# endregion
# region net parameter
Conv1_kernel_size = 11
Conv1_chs = 96
Conv2_kernel_size = 5
Conv2_chs = 256
Conv3_kernel_size = 3
Conv3_chs = 384
Conv4_kernel_size = 3
Conv4_chs = 384
Conv5_kernel_size = 3
Conv5_chs = 256
Flatten_size = 6 * 6 * 256
Fc1_size = 4096
Fc2_size = 4096
Fc3_size = Labels_nums
# endregion
# region hpyerparameter
Learning_rate = 1e-4
Batch_size = 32
Buffer_size = 256
Infer_size = 1
Epochs = 10
Train_num = 700
Train_batch_num = Train_num // Batch_size
Val_num = 100
Val_batch_num = Val_num // Batch_size
Test_num = 200
Test_batch_num = Test_num // Batch_size
# endregion
place = fluid.CUDAPlace(0) if fluid.cuda_places() else fluid.CPUPlace()
# endregion
class MyDataset():
def __init__(self, root_path, batch_size, files_list=None,):
self.root_path = root_path
self.files_list = files_list if files_list else os.listdir(root_path)
self.size = len(files_list)
self.batch_size = batch_size
def __len__(self):
return self.size
def dataset_reader(self):
pass
files_list = self.files_list if self.files_list is not None else os.listdir(self.root_path)
def reader():
np.random.shuffle(files_list)
for file_name in files_list:
label_str = file_name[:9]
label = list(Label_class.keys()).index(label_str)
img = Image.open(os.path.join(self.root_path, file_name))
yield img, label
return paddle.batch(paddle.reader.xmap_readers(self.transform, reader, 2, Buffer_size), batch_size=self.batch_size)
def transform(self,sample):
def Normalize(image, means, stds):
for band in range(len(means)):
image[:, :, band] = image[:, :, band] / 255.0
image[:, :, band] = (image[:, :, band] - means[band]) / stds[band]
image = np.transpose(image, [2, 1, 0])
return image
pass
image, label = sample
image = image.resize((Img_size, Img_size), Image.ANTIALIAS)
image = Normalize(np.array(image).astype(np.float), [0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
return image, label
class AlexNet:
def __init__(self, structShow=False):
self.structShow = structShow
self.image = data(shape=[Img_chs, Img_size, Img_size], dtype='float32', name='image')
self.label = data(shape=[Label_size], dtype='int64', name='label')
self.predict = self.get_alexNet()
def get_alexNet(self):
conv1 = conv2d(self.image, Conv1_chs, filter_size=Conv1_kernel_size, stride=4, padding=0, act='relu')
pool1 = pool2d(conv1, 3, pool_stride=2, pool_type='max')
conv2 = conv2d(pool1, Conv2_chs, filter_size=Conv2_kernel_size, padding=2, act='relu')
pool2 = pool2d(conv2, 3, pool_stride=2, pool_type='max')
conv3 = conv2d(pool2, Conv3_chs, filter_size=Conv3_kernel_size, padding=1, act='relu')
conv4 = conv2d(conv3, Conv4_chs, filter_size=Conv4_kernel_size, padding=1, act='relu')
conv5 = conv2d(conv4, Conv5_chs, filter_size=Conv5_kernel_size, padding=1, act='relu')
pool3 = pool2d(conv5, 3, pool_stride=2, pool_type='max')
flt = flatten(pool3, axis=1)
fc1 = fc(flt, Fc1_size, act='relu')
fc2 = fc(fc1, Fc2_size, act='relu')
fc3 = fc(fc1, Fc3_size, act='softmax')
if self.structShow:
print(conv1.name, conv1.shape)
print(pool1.name, pool1.shape)
print(conv2.name, conv2.shape)
print(pool2.name, pool2.shape)
print(conv3.name, conv3.shape)
print(conv4.name, conv4.shape)
print(conv5.name, conv5.shape)
print(pool3.name, pool3.shape)
print(flt.name, flt.shape)
print(fc1.name, fc1.shape)
print(fc2.name, fc2.shape)
print(fc3.name, fc3.shape)
return fc3
def train():
net = AlexNet(structShow=True)
image, label, predict = net.image, net.label, net.predict
feeder = fluid.DataFeeder(place=place, feed_list=[image, label])
df = pd.read_csv(Data_csv_path, header=0, index_col=0)
train_list = df[df['split'] == 'train']['filename'].tolist()
val_list = df[df['split'] == 'val']['filename'].tolist()
train_reader = MyDataset(Data_path, batch_size=Batch_size, files_list=train_list).dataset_reader()
val_reader = MyDataset(Data_path, batch_size=Batch_size, files_list=val_list).dataset_reader()
loss = cross_entropy(input=predict, label=label)
loss_mean = mean(loss)
acc = accuracy(input=predict, label=label)
optimizer = fluid.optimizer.AdamOptimizer(learning_rate=Learning_rate)
optimizer.minimize(loss_mean)
val_program = fluid.default_main_program().clone(for_test=True)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
train_losses = np.ones(Epochs)
train_accs = np.ones(Epochs)
val_losses = np.ones(Epochs)
val_accs = np.ones(Epochs)
best_loss = float("inf")
best_loss_epoch = 0
for epoch in range(Epochs):
print('Epoch %d/%d:' % (epoch + 1, Epochs))
train_sum_loss = 0
train_sum_acc = 0
val_sum_loss = 0
val_sum_acc = 0
for batch_num, data in enumerate(train_reader()):
train_loss, train_acc = exe.run(program=fluid.default_main_program(), # Run the main program
feed=feeder.feed(data), # Feed data to the model
fetch_list=[loss_mean, acc]) # fetch error and accuracy
train_sum_loss += train_loss[0]
train_sum_acc += train_acc[0]
process_show(batch_num + 1, Train_num / Batch_size, train_acc, train_loss, prefix='train:')
for batch_num, data in enumerate(val_reader()):
val_loss, val_acc = exe.run(program=val_program, # Perform training procedures
feed=feeder.feed(data), # Feed data
fetch_list=[loss_mean, acc]) # fetch error and accuracy
val_sum_loss += val_loss[0]
val_sum_acc += val_acc[0]
process_show(batch_num + 1, Val_num / Batch_size, val_acc, val_loss, prefix='train:')
train_sum_loss /= (Train_num // Batch_size)
train_sum_acc /= (Train_num // Batch_size)
val_sum_loss /= (Val_num // Batch_size)
val_sum_acc /= (Val_num // Batch_size)
train_losses[epoch] = train_sum_loss
train_accs[epoch] = train_sum_acc
val_losses[epoch] = val_sum_loss
val_accs[epoch] = val_sum_acc
print('average summary:\ntrain acc %.4f, loss %.4f ; val acc %.4f, loss %.4f'
% (train_sum_acc, train_sum_loss, val_sum_acc, val_sum_loss))
if val_sum_loss < best_loss:
print('val_loss improve from %.4f to %.4f, model save to %s ! \n' % (
best_loss, val_sum_loss, Model_file_paddle))
best_loss = val_sum_loss
best_loss_epoch = epoch + 1
fluid.io.save_inference_model(Model_file_paddle, # Path to save inference model
['image'], # inference requires the data of the feed
[predict], # The Variables that hold the inference results
exe) # The executor saves the information model
else:
print('val_loss do not improve from %.4f \n' % (best_loss))
print('best loss %.4f at epoch %d \n' % (best_loss, best_loss_epoch))
draw_loss_acc(train_losses, train_accs, 'train')
draw_loss_acc(val_losses, val_accs, 'val')
if __name__ == '__main__':
pass
# dataInfo_show(r'E:\_Python\01_deeplearning\03_AlexNet\data\my_imagenet',
# r'E:\_Python\01_deeplearning\03_AlexNet\data\my_imagenet.csv',
# r'E:\_Python\01_deeplearning\03_AlexNet\data\synset_words.txt')
# dataset_divide(r'E:\_Python\01_deeplearning\03_AlexNet\data\my_imagenet.csv')
train()
※ general ※ conclusion ※
summarize the basic network structure of AlexNet. Because the computing power required in the implementation of this network is relatively large. Again, it was not tested.
■ links to relevant literature:
- Alex net learning
- ImageNet Classification with Deep ConvolutionalNeural Networks
- Implementing AlexNet with padding
● relevant chart links: