Pretreatment
Before starting machine learning, it is often helpful to observe more data in the data set. For example, in the following email
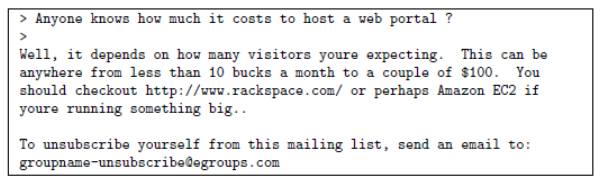
We can see a URL, an email address (at the end), numbers and dollar amounts.
Although many e-mail messages contain similar types of text (for example, numbers, other URL s, or other e-mail addresses), these texts are different in almost every e-mail message.
Therefore, a common way to deal with e-mail is to "standardize" these values so that all URLs are considered the same, all numbers are considered the same, and so on. For example, we can replace each URL in the email with a unique string "httpaddr" to indicate that there is a URL. This has the effect of allowing the spam classifier to make classification decisions based on the existence of any URL rather than the existence of a specific URL. This usually improves the performance of the spam classifier because spammers usually randomize URLs, so the chance of seeing any specific URL again in new spam is very small.
In processemail M, we implemented the following e-mail preprocessing and normalization steps:
- Lowercase: converts the entire email to lowercase, so uppercase is ignored (for example, treat IndIcaTE as the same as indicated).
- Split HTML: removes all HTML tags from the e-mail message. Many e-mails are usually in HTML format. We removed all HTML tags, so only the content was retained.
- Normalized URL: all URLs are replaced with the text "httpaddr".
- Standardized email address: all email addresses are replaced with the text "emailaddr".
- Normalized numbers: all numbers are replaced by the text "number".
- Standardized dollar: all dollar symbols ($) are replaced by the text "dollar".
- Stem: words are reduced to stem form. For example, 'discount', 'discounts',' discounted 'and' discounting 'are all replaced by' discount '. Sometimes, Stemmer actually strips additional characters from the end, so "include", "include", "include" and "include" are replaced with "include".
- Remove non words: remove non words and punctuation. All spaces (tabs, line breaks, spaces) have been trimmed to a single space character.
Thesaurus mapping
In addition, we also need to replace the words in the data with numbers, that is, replace the string with the index of the words in our thesaurus. The dictionary contains 1899 words that appear more than 100 times in all letters (if too many words are included, including those that appear only a few times, they are likely to appear).
In MATLAB, you can use the strcmp function to compare two strings. For example, strcmp(str1, str2) returns 1 only if two strings are equal. In the provided starting code, vocabList is a cell array containing words in the vocabulary. In MATLAB, except that its elements can also be strings (they cannot be in ordinary matlab matrices / vectors), cell array is like an ordinary array (i.e. vectors), which can be indexed by braces.
The functions of the first two parts are as follows:
function word_indices = processEmail(email_contents)
%PROCESSEMAIL preprocesses a the body of an email and
%returns a list of word_indices
% word_indices = PROCESSEMAIL(email_contents) preprocesses
% the body of an email and returns a list of indices of the
% words contained in the email.
%
% Load Vocabulary
vocabList = getVocabList();
% Init return value
word_indices = [];
% ========================== Preprocess Email ===========================
% Find the Headers ( \n\n and remove )
% Uncomment the following lines if you are working with raw emails with the
% full headers
% hdrstart = strfind(email_contents, ([char(10) char(10)]));
% email_contents = email_contents(hdrstart(1):end);
% Lower case
email_contents = lower(email_contents);
% Strip all HTML
% Looks for any expression that starts with < and ends with > and replace
% and does not have any < or > in the tag it with a space
email_contents = regexprep(email_contents, '<[^<>]+>', ' ');
% Handle Numbers
% Look for one or more characters between 0-9
email_contents = regexprep(email_contents, '[0-9]+', 'number');
% Handle URLS
% Look for strings starting with http:// or https://
email_contents = regexprep(email_contents, ...
'(http|https)://[^\s]*', 'httpaddr');
% Handle Email Addresses
% Look for strings with @ in the middle
email_contents = regexprep(email_contents, '[^\s]+@[^\s]+', 'emailaddr');
% Handle $ sign
email_contents = regexprep(email_contents, '[$]+', 'dollar');
% ========================== Tokenize Email ===========================
% Output the email to screen as well
fprintf('\n==== Processed Email ====\n\n');
% Process file
l = 0;
while ~isempty(email_contents)
% Tokenize and also get rid of any punctuation
[str, email_contents] = ...
strtok(email_contents, ...
[' @$/#.-:&*+=[]?!(){},''">_<;%' char(10) char(13)]);
% Remove any non alphanumeric characters
str = regexprep(str, '[^a-zA-Z0-9]', '');
% Stem the word
% (the porterStemmer sometimes has issues, so we use a try catch block)
try str = porterStemmer(strtrim(str));
catch str = ''; continue;
end;
% Skip the word if it is too short
if length(str) < 1
continue;
end
% Look up the word in the dictionary and add to word_indices if
% found
% ====================== YOUR CODE HERE ======================
% Instructions: Fill in this function to add the index of str to
% word_indices if it is in the vocabulary. At this point
% of the code, you have a stemmed word from the email in
% the variable str. You should look up str in the
% vocabulary list (vocabList). If a match exists, you
% should add the index of the word to the word_indices
% vector. Concretely, if str = 'action', then you should
% look up the vocabulary list to find where in vocabList
% 'action' appears. For example, if vocabList{18} =
% 'action', then, you should add 18 to the word_indices
% vector (e.g., word_indices = [word_indices ; 18]; ).
%
% Note: vocabList{idx} returns a the word with index idx in the
% vocabulary list.
%
% Note: You can use strcmp(str1, str2) to compare two strings (str1 and
% str2). It will return 1 only if the two strings are equivalent.
%
idx=find(strcmp(str,vocabList));
word_indices=[word_indices;idx];
% =============================================================
% Print to screen, ensuring that the output lines are not too long
if (l + length(str) + 1) > 78
fprintf('\n');
l = 0;
end
fprintf('%s ', str);
l = l + length(str) + 1;
end
% Print footer
fprintf('\n\n=========================\n');
end
After the first two steps, our letter will change from a letter to a number vector.
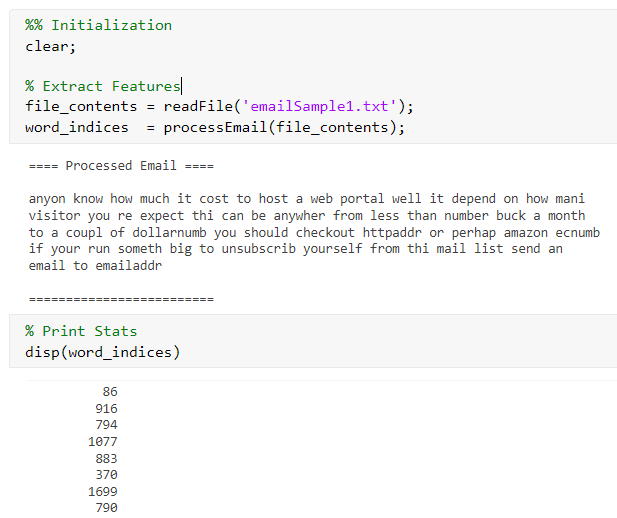
%% Initialization
clear;
% Extract Features
file_contents = readFile('emailSample1.txt');
word_indices = processEmail(file_contents);
% Print Stats
disp(word_indices)
Construct feature vector
For a letter, its feature vector is whether a word in the thesaurus has appeared in the letter. If so, the item is 1, if not, it is 0, which is very simple:
function x = emailFeatures(word_indices)
%EMAILFEATURES takes in a word_indices vector and produces a feature vector
%from the word indices
% x = EMAILFEATURES(word_indices) takes in a word_indices vector and
% produces a feature vector from the word indices.
% Total number of words in the dictionary
n = 1899;
% You need to return the following variables correctly.
x = zeros(n, 1);
% ====================== YOUR CODE HERE ======================
% Instructions: Fill in this function to return a feature vector for the
% given email (word_indices). To help make it easier to
% process the emails, we have have already pre-processed each
% email and converted each word in the email into an index in
% a fixed dictionary (of 1899 words). The variable
% word_indices contains the list of indices of the words
% which occur in one email.
%
% Concretely, if an email has the text:
%
% The quick brown fox jumped over the lazy dog.
%
% Then, the word_indices vector for this text might look
% like:
%
% 60 100 33 44 10 53 60 58 5
%
% where, we have mapped each word onto a number, for example:
%
% the -- 60
% quick -- 100
% ...
%
% (note: the above numbers are just an example and are not the
% actual mappings).
%
% Your task is take one such word_indices vector and construct
% a binary feature vector that indicates whether a particular
% word occurs in the email. That is, x(i) = 1 when word i
% is present in the email. Concretely, if the word 'the' (say,
% index 60) appears in the email, then x(60) = 1. The feature
% vector should look like:
%
% x = [ 0 0 0 0 1 0 0 0 ... 0 0 0 0 1 ... 0 0 0 1 0 ..];
%
%
for i=1:length(word_indices)
x(word_indices(i))=1;
end
% =========================================================================
end
train
After each letter in the data is processed above, we can carry out routine SVM training:
% Load the Spam Email dataset
% You will have X, y in your environment
load('spamTrain.mat');%The processed data is loaded here
C = 0.1;
model = svmTrain(X, y, C, @linearKernel);
p = svmPredict(model, X);
fprintf('Training Accuracy: %f\n', mean(double(p == y)) * 100);
% Load the test dataset
% You will have Xtest, ytest in your environment
load('spamTest.mat');
p = svmPredict(model, Xtest);
fprintf('Test Accuracy: %f\n', mean(double(p == ytest)) * 100);
Finally, the accuracy of the training set is obtained 99.85 % 99.85\% 99.85%, test set accuracy 98.9 % 98.9\% 98.9%
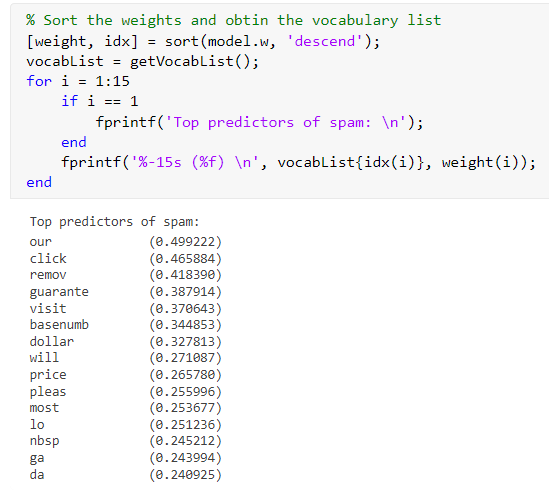
It's easier to see what our spam classifier contains as parameters:
% Sort the weights and obtin the vocabulary list
[weight, idx] = sort(model.w, 'descend');
vocabList = getVocabList();
for i = 1:15
if i == 1
fprintf('Top predictors of spam: \n');
end
fprintf('%-15s (%f) \n', vocabList{idx(i)}, weight(i));
end