Please note before reading:
1. MATLAB in-depth learning is an in-depth learning based on MATLAB learning notes. Learning this part requires a solid foundation of MATLAB. It is not recommended to learn this content without mastering the basic knowledge. The content of the blog is written and edited by @ K2SO4 potassium and published in the personal contribution of @ K2SO4 potassium and the official account of CSDN of HelloWorld programming Association of central China Normal University @ CCNU_HelloWorld . Note that if you need to reprint, you need the consent and authorization of the author @ K2SO4 potassium!
2. The codes and examples in the content are original by the author, and the references and other non original contents in the content will be marked at the end of the text in the form of references.
3. The example in the notes is MATLAB R2019a.
4. Please understand the possible errors in the notes and welcome correction and discussion; If the old code cannot be used due to MATLAB update, you are also welcome to discuss and exchange.
S1.0 MATLAB learning notes: portal summary
S1.0.1 MATLAB learning notes: portal summary
MATLAB learning notes 0: learning instructions
Matlab learning notes 1: overview of MATLAB
Matlab learning notes 2: basic knowledge of MATLAB (I)
Matlab learning notes 3: Fundamentals of MATLAB programming (first half)
Matlab learning notes 3: Fundamentals of MATLAB programming (second half)
S1.0.2 MATLAB extended learning: portal summary
MATLAB extended learning T1: anonymous functions and inline functions
MATLAB extended learning T2: program performance optimization technology
MATLAB extended learning T3: detailed explanation of histogram function
MATLAB extended learning T4: data import and table lookup Technology
S1.0.3 MATLAB in-depth learning: portal summary
In depth study of MATLAB S1: matlab implementation of simple digital filtering technology (1)
MATLAB in-depth study S2: infinite impulse response digital filter
MATLAB in-depth study S3: MATLAB implementation of simple digital filtering technology
In depth study of S4: cellular automata principle and MATLAB implementation
MATLAB in-depth study S5: image processing technology
S1.0.4 MATLAB application example: portal summary
MATLAB application example Y1: Floyd algorithm
S1.1 overview of digital filtering
For a signal, we often use filtering technology to retain the beneficial band and remove the useless band, noise and interference. However, in practice, there are often many strong interference sources in the industrial field. Under the action of environment such as temperature, electric field, magnetic field and humidity, combined with the interference caused by the equipment itself, a large number of random interference signals are often generated. The interference signal will not only affect the data collection of the equipment, but also affect the reliability of the controlled object and the whole system in the industrial process control system.
A few examples: the scale sometimes jumps violently due to the change of the center of gravity of the weighing person on the scale. Snowflakes will appear when there is a strong magnetic field near the computer mobile phone screen. The recording equipment often records some harsh noises when recording. When receiving a signal, it will also receive the interference signal of nearby interference sources, etc.
Digital filtering technology can enable the microcomputer system to process the collected sequence (smooth processing, etc.) while collecting analog signals, so that the useful signals account for most of the collected signals, reduce the interference and noise caused by environment, equipment itself and other factors as far as possible, and ensure the reliability of the system. Compared with the traditional analog filtering, digital filtering can set a processing program in the microcomputer, so that the computer system can process the signal while collecting the signal.
Digital filtering also plays an important role in computer image processing. Digital filtering technology can enable people to process pictures or videos (the video itself is also composed of multiple frames of pictures) in a procedural way to meet their needs. In many cases, digital filtering technology and image processing technology can make people better understand the world and deal with problems. For example, image enhancement technology and image denoising technology can make the key information of pictures more visible, and image classification and recognition technology can better serve the field of artificial intelligence. Digital filtering technology is closely related to the development of modern science and technology.
Compared with analog filtering technology, digital filtering technology has the following advantages: 1
- Digital filter can be placed between data processing and control algorithm in the form of program to reduce the consumption of hardware equipment;
- Reduce the instability of the hardware equipment to the system as much as possible (the hardware equipment itself will have a certain loss);
- Each channel of analog filter is usually dedicated, while digital filter can be shared by multiple channels to reduce cost;
- Due to the limitation of capacitance, analog filter can not filter very low frequency signals like digital filter;
- It is more flexible and convenient to use, and can carry out multiple filtering, a variety of different filtering methods, diversified and easy to adjust filtering parameters.
S1.2 common simple digital filtering techniques
S1.2.1 median filtering
S1.2.1.1 introduction to median filtering
Median filtering is effective for removing the error interference caused by the fluctuation caused by accidental factors or the error caused by the instability of the sampler. It has a good filtering effect on the controlled parameters with slow changes such as temperature and liquid level, but it is not suitable for the parameters with rapid changes such as flow and speed. The median filtering method is effective in filtering salt and pepper noise. 2
This is a picture I took from building 6 of Huashi Institute of mathematics and statistics to building 9 of the Institute of physics when I was playing the 2021 digital model national competition. The science building is very beautiful with blue sky and white clouds and lush forests.

t = imread('D:\Huawei Share\OneHop\IMG_20210912_122924.jpg');
Import this picture into MATLAB with imread function, and you will see a picture in the workspace 3000 ∗ 4000 ∗ 3 3000*4000*3 3000 * 4000 * 3 uint type matrix. This matrix describes the information of all pixels in this photo. 3000 ∗ 4000 3000*4000 3000 * 4000 indicates that this is a picture with a length of 3000 pixels and a width of 4000 pixels respectively, while the third dimension in the three-dimensional matrix stores R, G and B values in turn, describing the specific color of each pixel. The value of each element in the matrix is an integer from 0 to 255.
If you convert this RGB image to a grayscale image, you will see one in the workspace 3000 ∗ 4000 3000*4000 3000 * 4000 uint type matrix. Each element in the matrix describes the gray value of each pixel of the gray-scale photo. The larger the gray value, the closer it is to white, and the smaller the gray value, the closer it is to black.

t = rgb2gray(t);
Now, let's add some salt and pepper noise to the RGB picture:

t = imnoise(t,'salt & pepper',0.1); % The addition density is 0.1 Salt and pepper noise
The so-called "salt and pepper noise" refers to some random color impurities in RGB images and some random gray value impurities in gray images, also known as "impulse noise", which is a common noise in image processing. The following figure shows the clutter points of the RGB image with salt and pepper noise and the gray image with salt and pepper noise after amplification. Do you see the salt and pepper noise in the gray image below, like the salt and black pepper you sprinkled randomly on the chopping board?

Salt and pepper noise may be caused by sudden strong interference of image signal, analog-to-digital converter or bit transmission error. For example, a failed sensor causes the pixel value to be the minimum value, and a saturated sensor causes the pixel value to be the maximum value. The effective way to remove this noise is to use median filter. 3
A function, for example s i n sin sin function, if in s i n sin Some random disturbances are added at the random points of all sampling points of sin function. How to eliminate these disturbances as much as possible, the median filter method can also be considered.
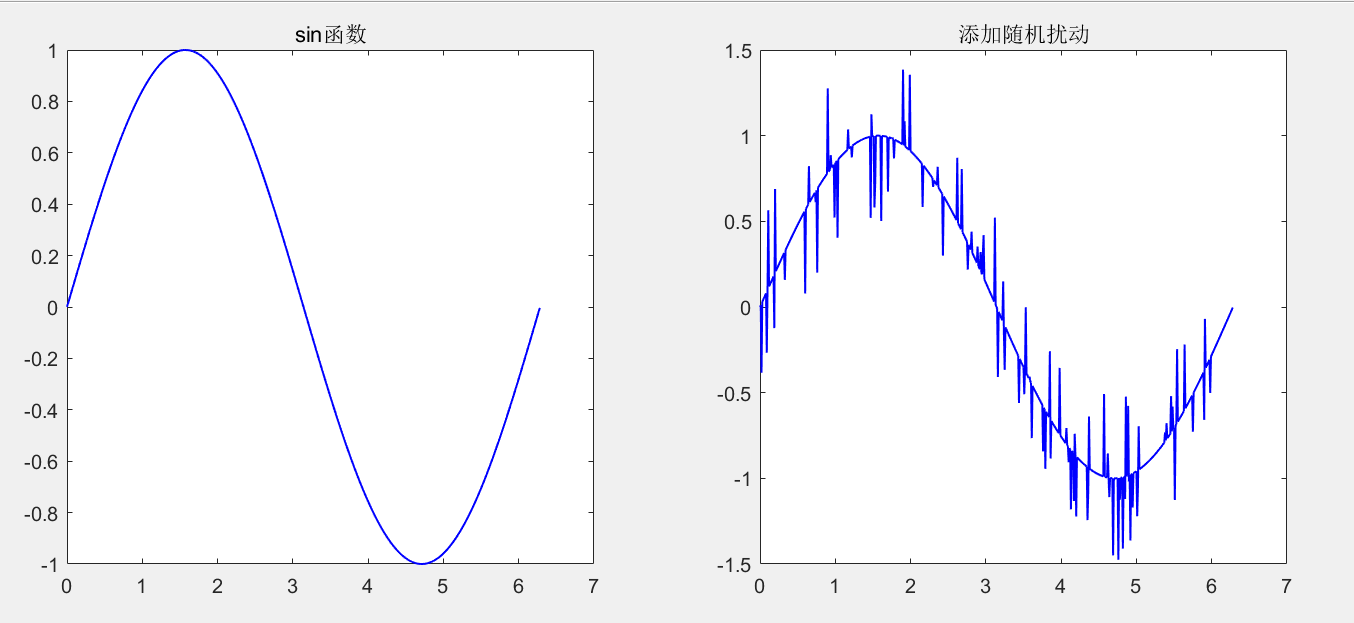
clc,clear all,close all
x = 0:0.01:2*pi;
y = sin(x);
subplot(121)
plot(x,y,'b-','LineWidth',1)
title('sin function')
noise = randi([1,length(x)],1,100);
y(1,noise) = y(1,noise)+randi([-500,500],1,length(noise))/1000;
subplot(122)
plot(x,y,'b-','LineWidth',1)
title('Add random disturbance')
S1.2.1.2 basic principle of median filtering
MATLAB has its own median filtering functions medfilt1 and medfilt2 to median filter one-dimensional sequence and two-dimensional data respectively. See the help document for detailed use methods. Here we mainly explain the basic principle and function creation of median filter.
The idea of median filter is very simple. For a certain point of the function, take several points near the point as the "sampling window", and replace the value of the point with the median of the value of the sampling window. For a pixel in the image, take several pixels near the pixel as the "sampling window", and replace the gray value or RGB value of the pixel with the median of the gray value or RGB value of the sampling window. However, in practical application, we often face the following problems:
1. How to select the size of sampling window?
The size of sampling window is different. For some functions or images, the final filtering results are also different.
The factors often considered in the selection of window size are: the density of noise, the size of sequence or image, the length and width of noise itself (if the window length and width is less than the noise length and width, it is difficult to remove noise by median filter), the rate of noise change, the cost of denoising and the running speed of the algorithm. Usually, a sequence will eventually get a stable sequence after several times of median filtering (the window is arbitrarily large, but the window size of each median filtering should be the same). This sequence is called the "root sequence". The root sequence is of great significance to the selection of median filter window size, which is not expanded here.
Usually, people will choose the best sampling window size according to experience and several experimental results.
2. How to select the shape of sampling window?
Similarly, people will choose the best sampling window shape according to experience and several experimental results. Common window shapes are: square, rectangle and cross. The example functions given below will also use these three graphs.
3. How to deal with the edge?
For any image processing technology, the edge is difficult to process. Because the median filtering algorithm needs to select the pixels around a pixel and take the median instead of the original pixel (if it is a function sequence, select the points near a point and take the median instead of the origin), the pixels (or points) at the edge cannot be processed by this method.
Common edge processing methods include Canny operator edge detection method, Laplace operator edge detection method, etc. it is not expanded here, and the following median filter function will not give the part of edge detection for the time being. For edge detection, please refer to this blog: Image filtering (median, mean) and edge detection (realized by matlab).
In addition to these, the median filtering method in practical application certainly needs to consider more problems. The implementation of median filtering in MATLAB will be more convenient than assembly, but the following points should be paid attention to:
The matrix corresponding to the image in MATLAB is uint8 type, and when processing the data, the type of data often becomes double. Finally, the matrix should be converted to uint8 type by forced conversion;
For a sampling window of any shape, there should be a center point. The median of all elements in the window will replace the value of the center point. The distance from the center point of the window to the edge of the window line is "cross arm", that is, C in the code_ arm; The distance from the center point of the window to the edge of the window column is "trailing arm", that is, R in the code_ arm;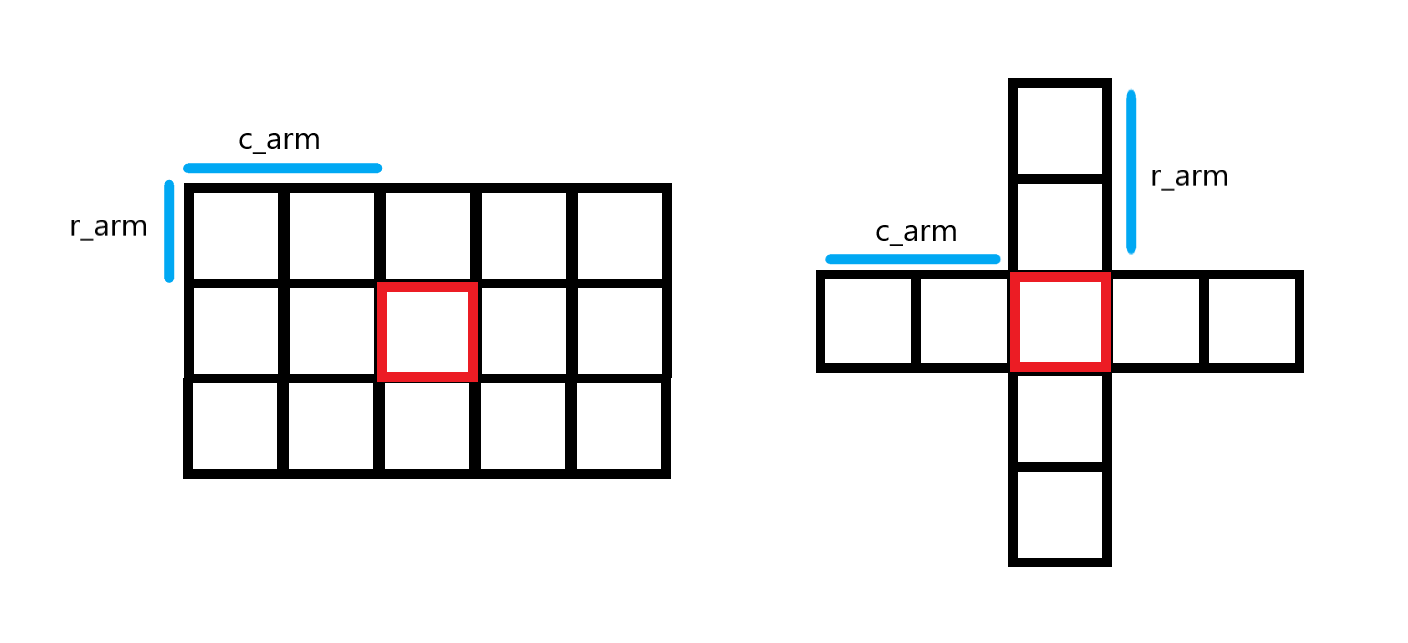
Due to the size of the window itself, the boundary of the image or sequence cannot be processed (at least we will not process the edge for the time being when discussing this section), so we can replace it with the edge value of the original image or the edge value of the original sequence. In addition, it should be noted that when processing the median value of each point in the cycle, do not also process the edge value (otherwise the window will extend outside the image and an error will be reported).
An original and complete median filter function, median, is given below_ For detailed functions and usage of filter, please check the help document of this function.
function [Output1, Output2] = Median_Filter(Method, Input1, Input2, Window, Window_type, Edge_Check, Drawing)
%
% Return the median filtering result for binary image, RGB image
% or function image in rectangular coordinate system.
%
% Median_Filter Function is used to return a binary image RGB Median filtering result of function image in image or rectangular coordinate system
%
% input parameter Method: The values can be 1, 2 and 3, and errors will be reported for other values
% > Method = 1 The function image in rectangular coordinate system is median filtered
% > Method = 2 The binary image is median filtered
% > Method = 3 Time right RGB Image median filtering
% input parameter Input:
% > if Method = 1,be Input1,Input2 Enter the values of the abscissa and ordinate corresponding to the function (all line vectors),
% perhaps Input1 Enter an empty matrix, Input2 Enter the ordinate value, and the function will automatically fill in the abscissa from 1
% > if Method = 2,be Input1 Enter the two-dimensional matrix of the binary image, Input2 Input null matrix
% > if Method = 3,be Input1 input RGB 3D matrix of image
% input parameter Window: The window size of the median filter (the elements in the matrix should be positive integers. If the input is a double precision number, it will be rounded down)
% input parameter Window_type: Window type
% > if Window_type = 'default'(That is, the window is a row vector)
% ·Method = 1 When, Window Take one less than Input2 Integer of vector length, indicating the window length (should be an odd number greater than 1)
% ·Method An error will be reported when taking other values
% > if Window_type = 'square'(That is, the window is square)
% ·Method = 1 An error will be reported when
% ·if Method = 2 Or 3, Window Take one less than Input1 The integer of the row width of the matrix, indicating the window side length (should be an odd number greater than 1)
% > if Window_type = 'rectangle'(That is, the window is rectangular)
% ·Method = 1 An error will be reported when
% ·if Method = 2 Or 3, Window Take one less than Input1 Matrix row width 1*2 Vector, representing window length and width respectively (both should be odd numbers greater than 1)
% > if Window_type = 'cross'(That is, the window is cross shaped)
% ·Method = 1 An error will be reported when
% ·if Method = 2 Or 3, Window Take one less than Input1 Matrix row width 1*2 Vector, respectively representing the length and width of the cross window (both should be odd numbers greater than 1)
% > if Method = 3,If necessary R,G,B For median filtering with different window sizes, please enter 3*2 Or 3*1 Matrix of (apparent) Window_type As appropriate),
% Each line represents a pair R,G,B Window size for median filtering
% input parameter Edge_Check: Edge detection method
% > 'none'(Default): no edge detection
% input parameter Drawing: Whether to draw or display images in functions
% > 'off'(Default): do not display images
% > 'on': Display image
%
% Output parameters Output1: Method = 1 The abscissa vector of the processing result is output; Method = 2 Or 3, the matrix corresponding to the output image
% Output parameters Output2: Method = 1 When processing, the ordinate vector of the processing result is output; Method = 2 Or 3 hours Output2 Empty
%
% Common calling methods:
% [Output1, Output2] = Median_Filter(Method, Input1, Input2, Window, Window_type)
% [Output1, Output2] = Median_Filter(Method, Input1, Input2, Window, Window_type, Edge_Check, Drawing)
%
% Prepared on October 6, 2021:32 programmer: K2SO4 Potassium (Central China Normal University)
%% Initial judgment error and warning
% Set initial parameters
if isempty(Input1)
r_length = size(Input2,1);
c_length = size(Input2,2);
else
r_length = size(Input1,1);
c_length = size(Input1,2);
end
if nargin == 4
Window_type = 'default';
Edge_Check = 'none';
Drawing = 'off';
elseif nargin == 5
Edge_Check = 'none';
Drawing = 'off';
elseif nargin == 6
if strcmp(Edge_Check,'on') || strcmp(Edge_Check,'off')
Drawing = Edge_Check;
Edge_Check = 'none';
else
Drawing = 'off';
end
end
% Input / output parameter specification
if nargin >= 8
error('Too many input parameters')
elseif nargin <= 3
error('Too few input parameters')
end
if nargout >= 3
error('Too many output parameters')
end
% Method Parameter specification
Method = floor(Method);
if Method >= 4 || Method < 1
error('Method The value of is specified as 1, 2 and 3. After rounding down, the input value outside the specified value will report an error')
end
% Method = 1 Time regulation Input1,Input2 Expected an equal length row vector
if Method == 1
if ~isempty(Input1)
if size(Input1,1) ~= 1 || size(Input2,1) ~= 1
error('Input1 When not empty, Input1,Input2 Expected an equal length row vector')
end
if length(Input1) ~= length(Input2)
error('Input1 When not empty, Input1,Input2 Expected an equal length row vector')
end
else
if size(Input2,1) ~= 1
error('Input2 Expected row vector')
end
end
end
% Method = 2,3 Time regulation Input1 The length and width of must be within 3*3 above
if Method == 2 || Method == 3
if size(Input1,1) <= 3 || size(Input1,2) <= 3
error('Method = 2,3 Time regulation Input1 The length and width of must be within 3*3 above')
end
if ~isempty(Input2)
warning('Will ignore Input2 Input of')
end
end
% The window size should be set to a positive integer, an odd number greater than 1, and the window length or width should be less than or equal to the length of the function dependent variable or the length and width of the image
Window = floor(Window);
if sum(sum(Window < 3)) ~= 0
error('The window size should be set to a positive integer and an odd number greater than 1')
end
if Method == 1
if Window > c_length
error(error('The window length or width should be less than or equal to the function dependent variable length or image width'))
end
elseif strcmp(Window_type,'square')
if max(Window(:,1)) > r_length || max(Window(:,1)) > c_length
error(error('The window length or width should be less than or equal to the function dependent variable length or image width'))
end
else
if max(Window(:,1)) > r_length || max(Window(:,2)) > c_length
error('The window length or width should be less than or equal to the function dependent variable length or image width')
end
end
% Method And Window_type Collocation does not meet the requirements. For details, please type help Median_Filter
if Method == 1
if ~(strcmp(Window_type,'default'))
error('Method And Window_type Collocation does not meet the requirements. For details, please type help Median_Filter')
end
else
if ~((strcmp(Window_type,'square')) || (strcmp(Window_type,'rectangle')) || (strcmp(Window_type,'cross')))
error('Method And Window_type Collocation does not meet the requirements. For details, please type help Median_Filter')
end
end
% Window The size of the matrix does not meet the specification. Enter parameters according to rules Window,For details, please type help Median_Filter
if Method == 1
if size(Window,1)*size(Window,2) ~= 1
error('Window The size of the matrix does not meet the specification. Enter parameters according to rules Window,For details, please type help Median_Filter')
end
elseif strcmp(Window_type,'square')
if ~((size(Window,1) == 1 && size(Window,2) == 1) || (size(Window,1) == 3 && size(Window,2) == 1))
error('Window The size of the matrix does not meet the specification. Enter parameters according to rules Window,For details, please type help Median_Filter')
end
else
if ~((size(Window,1) == 1 && size(Window,2) == 2) || (size(Window,1) == 3 && size(Window,2) == 2))
error('Window The size of the matrix does not meet the specification. Enter parameters according to rules Window,For details, please type help Median_Filter')
end
end
% Specifies that the window size must be odd
if mean(mean(round(mod(Window,2)))) ~= 1
error('Specifies that the length and width of the window must be odd')
end
% Please input parameters as specified Edge_Check. For details, please type help Median_Filter
if ~strcmp(Edge_Check,'none')
error('Please input parameters as specified Edge_Check. For details, please type help Median_Filter')
end
if strcmp(Edge_Check,'none')
warning('No function or image edge detection and processing!')
end
% Please input parameters as specified Drawing. For details, please type help Median_Filter
if ~(strcmp(Drawing,'on') || strcmp(Drawing,'off'))
error('Please input parameters as specified Drawing. For details, please type help Median_Filter')
end
%% Function core
if Method == 1
if isempty(Input1)
Input1 = 1:length(Input2);
end
New = zeros(size(Input1,1),size(Input1,2));
arm = floor(Window/2);
area = arm+1:length(Input1)-arm;
if strcmp(Edge_Check,'none') % No edge treatment
for i = 1:arm
New(1,i) = Input2(1,i);
end
for i = length(Input1)-arm+1:length(Input1)
New(1,i) = Input2(1,i);
end
end
%%%%%%%%%%%%%%%%%%%
% Edge treatments can be added later here
%%%%%%%%%%%%%%%%%%%
for i = area % core
M = Input2(1,i-arm:i+arm);
New(1,i) = median(M);
end
Output1 = Input1; % output
Output2 = New;
if strcmp(Drawing,'on') % Detect whether to draw
figure
subplot(121)
plot(Input1,Input2,'b-','LineWidth',1)
grid on
title('Original input')
subplot(122)
plot(Output1,Output2,'b-','LineWidth',1)
grid on
title('After median filtering')
end
end
if Method == 2
New = zeros(size(Input1,1),size(Input1,2));
if strcmp(Window_type,'square') || strcmp(Window_type,'rectangle') || strcmp(Window_type,'cross')
if size(Window,2) == 1
r_arm = floor(Window/2);
c_arm = r_arm;
elseif size(Window,2) == 2
r_arm = floor(Window(1,2)/2); % Longitudinal arm length
c_arm = floor(Window(1,1)/2); % Cross arm length
end
end
r_area = r_arm+1:r_length-r_arm;
c_area = c_arm+1:c_length-c_arm;
if strcmp(Edge_Check,'none') % No edge treatment
for i = 1:r_arm
New(i,:) = Input1(i,:);
end
for i = r_length-r_arm+1:r_length
New(i,:) = Input1(i,:);
end
for j = 1:c_arm
New(:,j) = Input1(:,j);
end
for j = c_length-c_arm+1:c_length
New(:,j) = Input1(:,j);
end
end
%%%%%%%%%%%%%%%%%%%
% Edge treatments can be added later here
%%%%%%%%%%%%%%%%%%%
if strcmp(Window_type,'square') || strcmp(Window_type,'rectangle') % core
for i = r_area
for j = c_area
M = Input1(i-r_arm:i+r_arm,j-c_arm:j+c_arm);
New(i,j) = median(median(M));
end
end
elseif strcmp(Window_type,'cross')
for i = r_area
for j = c_area
M = [Input1(i-r_arm:i+r_arm,j)',Input1(i,j-c_arm:j+c_arm)];
New(i,j) = median(median(M));
end
end
end
Output1 = New; % output
Output1 = uint8(Output1);
Output2 = [];
if strcmp(Drawing,'on') % Detect whether to draw
subplot(121)
imshow(Input1)
title('Original picture')
subplot(122)
imshow(Output1)
title('Median filtered image')
end
end
if Method == 3
New = zeros(r_length,c_length,3);
if strcmp(Window_type,'square') || strcmp(Window_type,'rectangle') || strcmp(Window_type,'cross')
if size(Window,2) == 1
if size(Window,1) == 1
R_r_arm = floor(Window/2); % Red longitudinal arm length
R_c_arm = R_r_arm; % Red cross arm length
G_r_arm = floor(Window/2); % Green longitudinal arm length
G_c_arm = G_r_arm; % Green cross arm length
B_r_arm = floor(Window/2); % Blue longitudinal arm length
B_c_arm = B_r_arm; % Blue cross arm length
elseif size(Window,1) == 3
R_r_arm = floor(Window(1,1)/2); % Red longitudinal arm length
R_c_arm = R_r_arm; % Red cross arm length
G_r_arm = floor(Window(2,1)/2); % Green longitudinal arm length
G_c_arm = G_r_arm; % Green cross arm length
B_r_arm = floor(Window(3,1)/2); % Blue longitudinal arm length
B_c_arm = B_r_arm; % Blue cross arm length
end
elseif size(Window,2) == 2
if size(Window,1) == 1
R_r_arm = floor(Window(1,2)/2); % Red longitudinal arm length
R_c_arm = floor(Window(1,1)/2); % Red cross arm length
G_r_arm = floor(Window(1,2)/2); % Green longitudinal arm length
G_c_arm = floor(Window(1,1)/2); % Green cross arm length
B_r_arm = floor(Window(1,2)/2); % Blue longitudinal arm length
B_c_arm = floor(Window(1,1)/2); % Blue cross arm length
elseif size(Window,1) == 3
R_r_arm = floor(Window(1,2)/2); % Red longitudinal arm length
R_c_arm = floor(Window(1,1)/2); % Red cross arm length
G_r_arm = floor(Window(2,2)/2); % Green longitudinal arm length
G_c_arm = floor(Window(2,1)/2); % Green cross arm length
B_r_arm = floor(Window(3,2)/2); % Blue longitudinal arm length
B_c_arm = floor(Window(3,1)/2); % Blue cross arm length
end
end
end
R_r_area = R_r_arm+1:r_length-R_r_arm;
R_c_area = R_c_arm+1:c_length-R_c_arm;
G_r_area = G_r_arm+1:r_length-G_r_arm;
G_c_area = G_c_arm+1:c_length-G_c_arm;
B_r_area = B_r_arm+1:r_length-B_r_arm;
B_c_area = B_c_arm+1:c_length-B_c_arm;
if strcmp(Edge_Check,'none') % No edge treatment
for k = 1:3
if k == 1
r_arm = R_r_arm;
c_arm = R_c_arm;
elseif k == 2
r_arm = G_r_arm;
c_arm = G_c_arm;
else
r_arm = B_r_arm;
c_arm = B_c_arm;
end
for i = 1:r_arm
New(i,:,k) = Input1(i,:,k);
end
for i = r_length-r_arm+1:r_length
New(i,:,k) = Input1(i,:,k);
end
for j = 1:c_arm
New(:,j,k) = Input1(:,j,k);
end
for j = c_length-c_arm+1:c_length
New(:,j,k) = Input1(:,j,k);
end
end
end
%%%%%%%%%%%%%%%%%%%
% Edge treatments can be added later here
%%%%%%%%%%%%%%%%%%%
for k = 1:3 % core
if k == 1
r_arm = R_r_arm;
c_arm = R_c_arm;
r_area = R_r_area;
c_area = R_c_area;
elseif k == 2
r_arm = G_r_arm;
c_arm = G_c_arm;
r_area = G_r_area;
c_area = G_c_area;
else
r_arm = B_r_arm;
c_arm = B_c_arm;
r_area = B_r_area;
c_area = B_c_area;
end
if strcmp(Window_type,'square') || strcmp(Window_type,'rectangle') % core
for i = r_area
for j = c_area
M = Input1(i-r_arm:i+r_arm,j-c_arm:j+c_arm,k);
New(i,j,k) = median(median(M));
end
end
elseif strcmp(Window_type,'cross')
for i = r_area
for j = c_area
M = [Input1(i-r_arm:i+r_arm,j,k)',Input1(i,j-c_arm:j+c_arm,k)];
New(i,j,k) = median(median(M));
end
end
end
Output1 = New; % output
Output1 = uint8(Output1);
Output2 = [];
if strcmp(Drawing,'on') % Detect whether to draw
subplot(121)
imshow(Input1)
title('Original picture')
subplot(122)
imshow(Output1)
title('Median filtered image')
end
end
end
end
S1.2.1.3 test of median filter function
Test the filtering effect of the function.
1. For sequences with low noise density
The first median filtering is performed on the sequence, and the filtering effect is good:
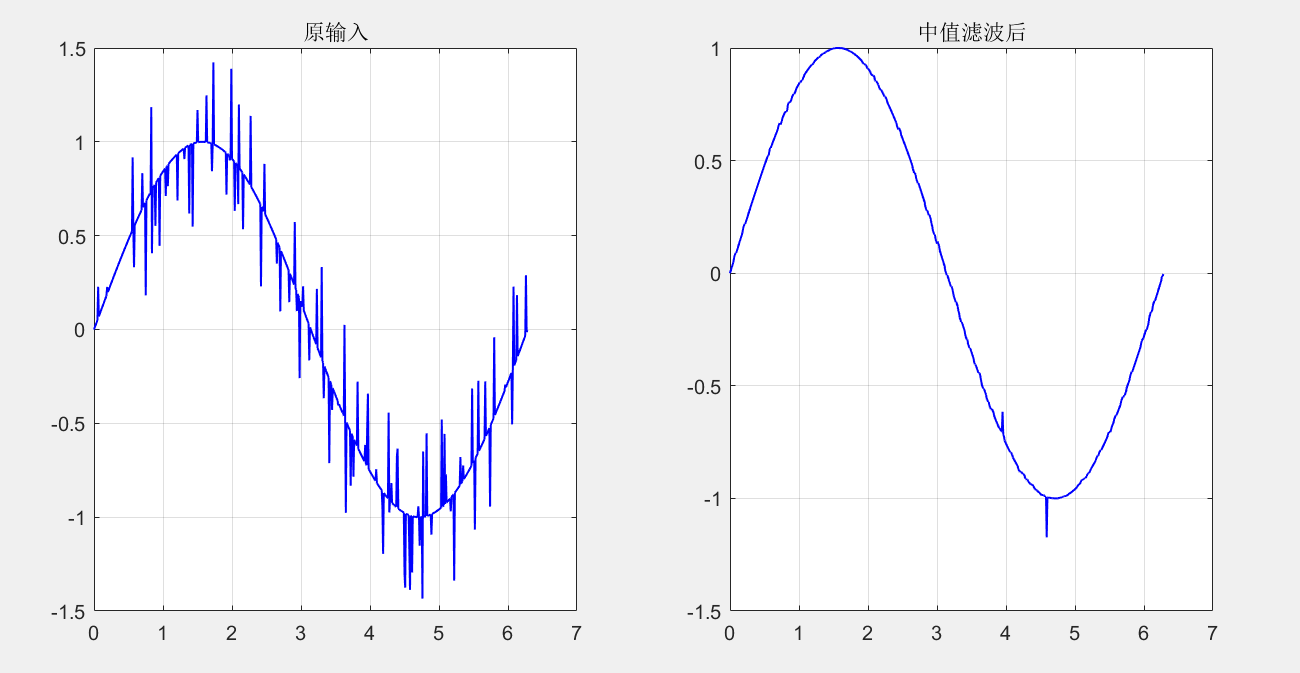
clc,clear all,close all x = 0:0.01:2*pi; y = sin(x); noise = randi([1,length(x)],1,100); y(1,noise) = y(1,noise)+randi([-500,500],1,length(noise))/1000; [ans1,ans2] = Median_Filter(1,x,y,5,'default','none','on'); % 5*5 Square window median filter
The second median filtering is performed on the sequence, and the filtering result basically restores the original signal:
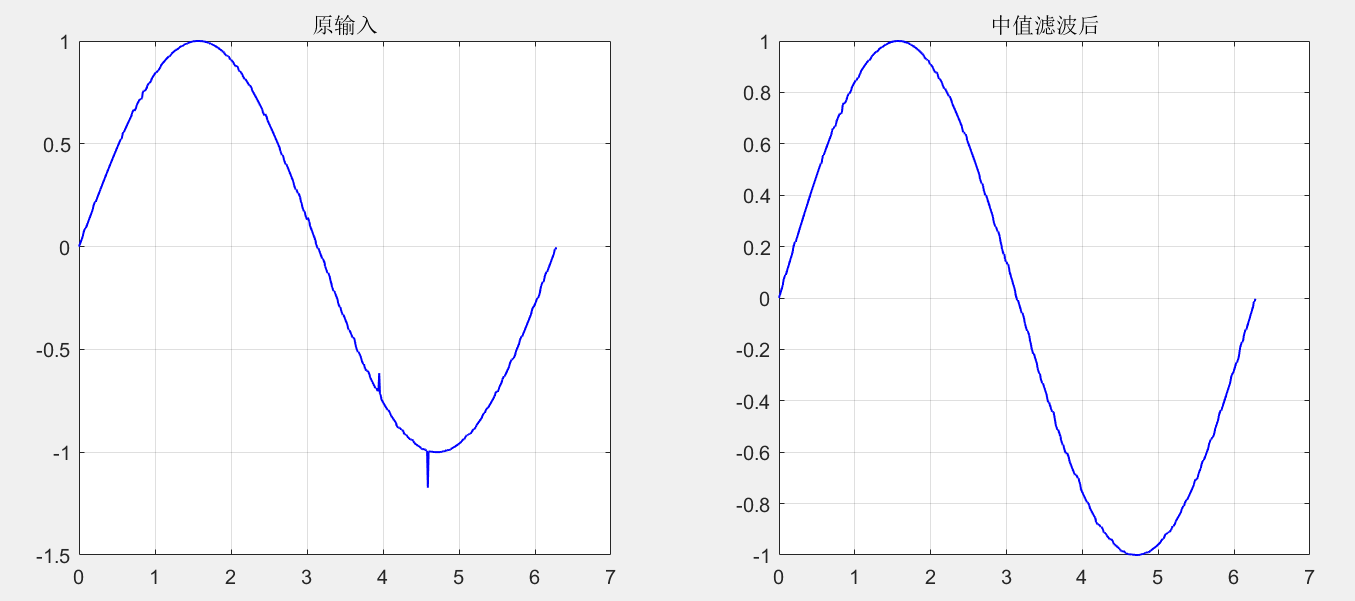
[ans1,ans2] = Median_Filter(1,ans1,ans2,7,'default','none','on'); % 7*7 Square window median filter
2. For sequences with high noise density
The first filtering effect is not significant:
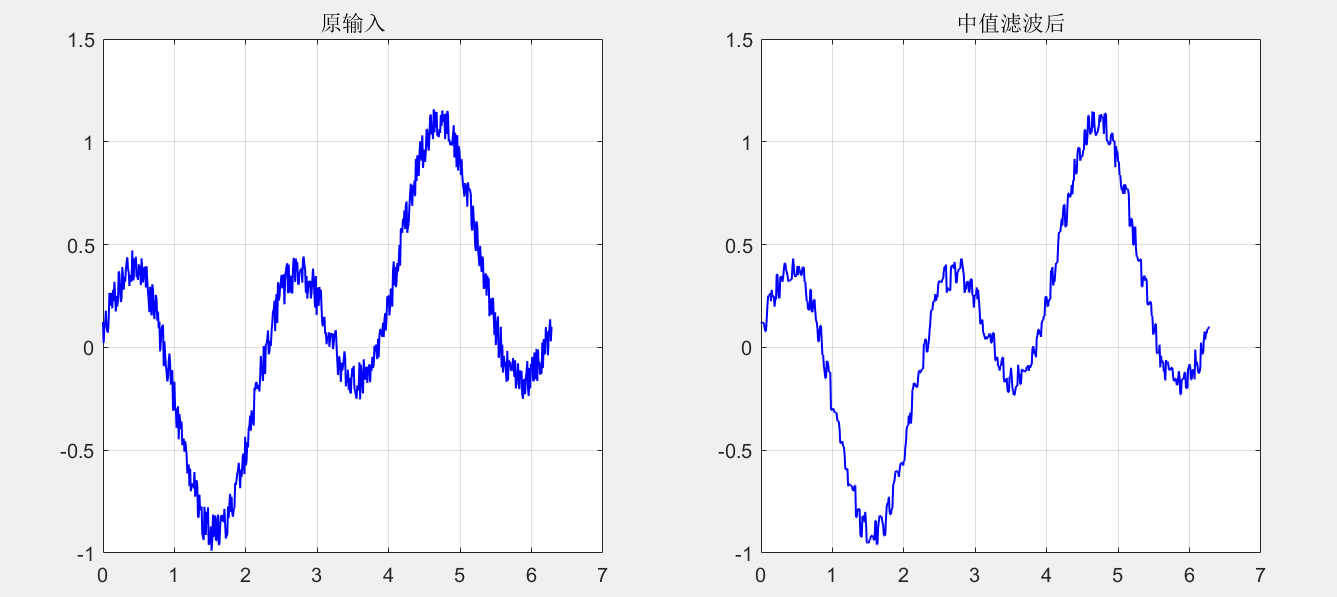
clc,clear all,close all x = 0:0.01:2*pi; y = sin(x).*cos(2*x)+0.2*rand(1,length(x)); [ans1,ans2] = Median_Filter(1,x,y,3,'default','none','on');
After the second filtering, the original signal shape can be restored, but the effect is poor:
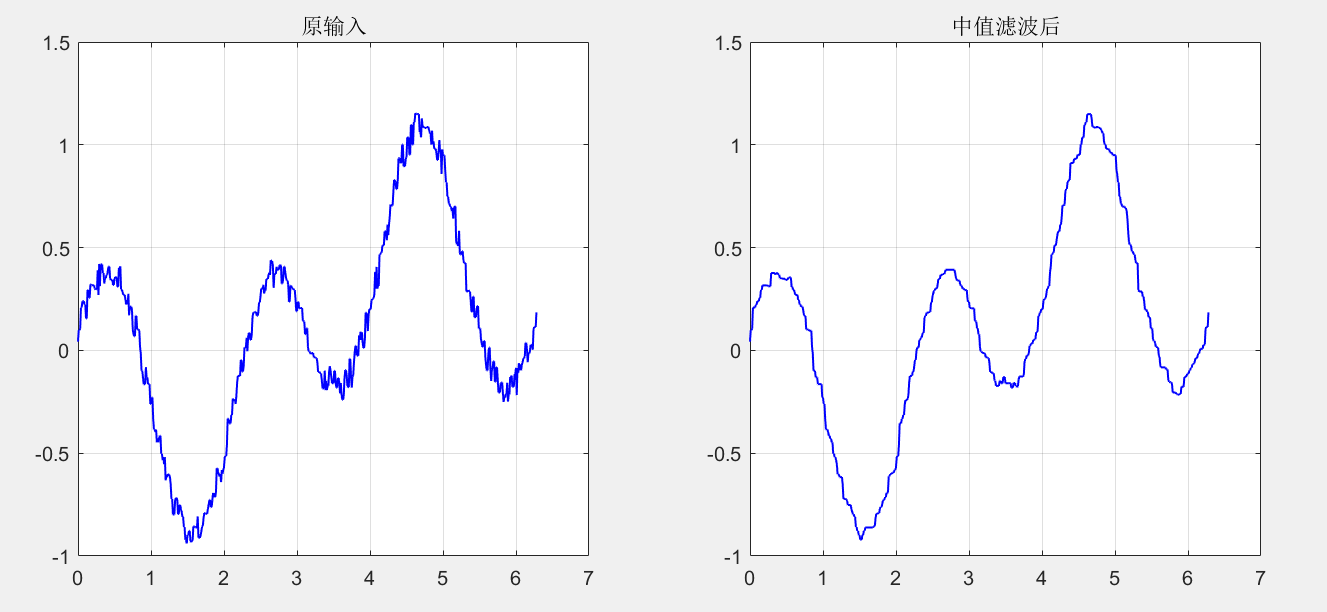
[ans1,ans2] = Median_Filter(1,ans1,ans2,11,'default','none','on');
3. For gray image with salt and pepper noise
The first filtering effect is quite good:

clc,clear all,close all
t = imread('D:\Huawei Share\OneHop\IMG_20210912_122924.jpg');
t = rgb2gray(t);
t = imnoise(t,'salt & pepper',0.1); % The addition density is 0.1 Salt and pepper noise
[ans1,ans2] = Median_Filter(2,t,[],3,'square','none','on'); % 3*3 Square window median filter
The second filtering basically removes most of the salt and pepper pixels:

[ans3,ans4] = Median_Filter(2,ans1,[],3,'square','none','on'); % Second median filter
4. For RGB images with salt and pepper noise
Significant image filtering effect:

clc,clear all,close all
t = imread('D:\Huawei Share\OneHop\IMG_20210912_122924.jpg');
t = imnoise(t,'salt & pepper',0.1); % The addition density is 0.1 Salt and pepper noise
[ans1,ans2] = Median_Filter(3,t,[],[3;3;3],'square','none','on'); % 3*3 Square window median filter
Because the code has not been optimized, the running time for image processing will be too long.
S1.2.2 arithmetic mean filtering
Arithmetic mean filtering is only different from median filtering in the core section of the function.
function [Output1, Output2] = Mean_Filter(Method, Input1, Input2, Window, Window_type, Edge_Check, Drawing)
%
% Return the mean filtering result for binary image, RGB image
% or function image in rectangular coordinate system.
%
% Mean_Filter Function is used to return a binary image RGB Arithmetic mean filtering result of function image in image or rectangular coordinate system
%
% input parameter Method: The values can be 1, 2 and 3, and errors will be reported for other values
% > Method = 1 Arithmetic mean filtering is performed on the function image in rectangular coordinate system
% > Method = 2 Arithmetic mean filtering is performed on the binary image
% > Method = 3 Time right RGB The image is filtered by arithmetic mean
% input parameter Input:
% > if Method = 1,be Input1,Input2 Enter the values of the abscissa and ordinate corresponding to the function (all line vectors),
% perhaps Input1 Enter an empty matrix, Input2 Enter the ordinate value, and the function will automatically fill in the abscissa from 1
% > if Method = 2,be Input1 Enter the two-dimensional matrix of the binary image, Input2 Input null matrix
% > if Method = 3,be Input1 input RGB 3D matrix of image
% input parameter Window: The window size of the arithmetic mean filter (the elements in the matrix should be positive integers. If the input is a double precision number, it will be rounded down)
% input parameter Window_type: Window type
% > if Window_type = 'default'(That is, the window is a row vector)
% ·Method = 1 When, Window Take one less than Input2 Integer of vector length, indicating the window length (should be an odd number greater than 1)
% ·Method An error will be reported when taking other values
% > if Window_type = 'square'(That is, the window is square)
% ·Method = 1 An error will be reported when
% ·if Method = 2 Or 3, Window Take one less than Input1 The integer of the row width of the matrix, indicating the window side length (should be an odd number greater than 1)
% > if Window_type = 'rectangle'(That is, the window is rectangular)
% ·Method = 1 An error will be reported when
% ·if Method = 2 Or 3, Window Take one less than Input1 Matrix row width 1*2 Vector, representing window length and width respectively (both should be odd numbers greater than 1)
% > if Window_type = 'cross'(That is, the window is cross shaped)
% ·Method = 1 An error will be reported when
% ·if Method = 2 Or 3, Window Take one less than Input1 Matrix row width 1*2 Vector, respectively representing the length and width of the cross window (both should be odd numbers greater than 1)
% > if Method = 3,If necessary R,G,B For arithmetic mean filtering of different window sizes, please enter 3*2 Or 3*1 Matrix of (apparent) Window_type As appropriate),
% Each line represents a pair R,G,B Window size for arithmetic mean filtering
% input parameter Edge_Check: Edge detection method
% > 'none'(Default): no edge detection
% input parameter Drawing: Whether to draw or display images in functions
% > 'off'(Default): do not display images
% > 'on': Display image
%
% Output parameters Output1: Method = 1 The abscissa vector of the processing result is output; Method = 2 Or 3, the matrix corresponding to the output image
% Output parameters Output2: Method = 1 When processing, the ordinate vector of the processing result is output; Method = 2 Or 3 hours Output2 Empty
%
% Common calling methods:
% [Output1, Output2] = Mean_Filter(Method, Input1, Input2, Window, Window_type)
% [Output1, Output2] = Mean_Filter(Method, Input1, Input2, Window, Window_type, Edge_Check, Drawing)
%
% Prepared on October 6, 2021:32 programmer: K2SO4 Potassium (Central China Normal University)
%% Initial judgment error and warning
% Set initial parameters
if isempty(Input1)
r_length = size(Input2,1);
c_length = size(Input2,2);
else
r_length = size(Input1,1);
c_length = size(Input1,2);
end
if nargin == 4
Window_type = 'default';
Edge_Check = 'none';
Drawing = 'off';
elseif nargin == 5
Edge_Check = 'none';
Drawing = 'off';
elseif nargin == 6
if strcmp(Edge_Check,'on') || strcmp(Edge_Check,'off')
Drawing = Edge_Check;
Edge_Check = 'none';
else
Drawing = 'off';
end
end
% Input / output parameter specification
if nargin >= 8
error('Too many input parameters')
elseif nargin <= 3
error('Too few input parameters')
end
if nargout >= 3
error('Too many output parameters')
end
% Method Parameter specification
Method = floor(Method);
if Method >= 4 || Method < 1
error('Method The value of is specified as 1, 2 and 3. After rounding down, the input value outside the specified value will report an error')
end
% Method = 1 Time regulation Input1,Input2 Expected an equal length row vector
if Method == 1
if ~isempty(Input1)
if size(Input1,1) ~= 1 || size(Input2,1) ~= 1
error('Input1 When not empty, Input1,Input2 Expected an equal length row vector')
end
if length(Input1) ~= length(Input2)
error('Input1 When not empty, Input1,Input2 Expected an equal length row vector')
end
else
if size(Input2,1) ~= 1
error('Input2 Expected row vector')
end
end
end
% Method = 2,3 Time regulation Input1 The length and width of must be within 3*3 above
if Method == 2 || Method == 3
if size(Input1,1) <= 3 || size(Input1,2) <= 3
error('Method = 2,3 Time regulation Input1 The length and width of must be within 3*3 above')
end
if ~isempty(Input2)
warning('Will ignore Input2 Input of')
end
end
% The window size should be set to a positive integer, an odd number greater than 1, and the window length or width should be less than or equal to the length of the function dependent variable or the length and width of the image
Window = floor(Window);
if sum(sum(Window < 3)) ~= 0
error('The window size should be set to a positive integer and an odd number greater than 1')
end
if Method == 1
if Window > c_length
error(error('The window length or width should be less than or equal to the function dependent variable length or image width'))
end
elseif strcmp(Window_type,'square')
if max(Window(:,1)) > r_length || max(Window(:,1)) > c_length
error(error('The window length or width should be less than or equal to the function dependent variable length or image width'))
end
else
if max(Window(:,1)) > r_length || max(Window(:,2)) > c_length
error('The window length or width should be less than or equal to the function dependent variable length or image width')
end
end
% Method And Window_type Collocation does not meet the requirements. For details, please type help Mean_Filter
if Method == 1
if ~(strcmp(Window_type,'default'))
error('Method And Window_type Collocation does not meet the requirements. For details, please type help Mean_Filter')
end
else
if ~((strcmp(Window_type,'square')) || (strcmp(Window_type,'rectangle')) || (strcmp(Window_type,'cross')))
error('Method And Window_type Collocation does not meet the requirements. For details, please type help Mean_Filter')
end
end
% Window The size of the matrix does not meet the specification. Enter parameters according to rules Window,For details, please type help Mean_Filter
if Method == 1
if size(Window,1)*size(Window,2) ~= 1
error('Window The size of the matrix does not meet the specification. Enter parameters according to rules Window,For details, please type help Mean_Filter')
end
elseif strcmp(Window_type,'square')
if ~((size(Window,1) == 1 && size(Window,2) == 1) || (size(Window,1) == 3 && size(Window,2) == 1))
error('Window The size of the matrix does not meet the specification. Enter parameters according to rules Window,For details, please type help Mean_Filter')
end
else
if ~((size(Window,1) == 1 && size(Window,2) == 2) || (size(Window,1) == 3 && size(Window,2) == 2))
error('Window The size of the matrix does not meet the specification. Enter parameters according to rules Window,For details, please type help Mean_Filter')
end
end
% Specifies that the window size must be odd
if mean(mean(round(mod(Window,2)))) ~= 1
error('Specifies that the length and width of the window must be odd')
end
% Please input parameters as specified Edge_Check. For details, please type help Mean_Filter
if ~strcmp(Edge_Check,'none')
error('Please input parameters as specified Edge_Check. For details, please type help Mean_Filter')
end
if strcmp(Edge_Check,'none')
warning('No function or image edge detection and processing!')
end
% Please input parameters as specified Drawing. For details, please type help Mean_Filter
if ~(strcmp(Drawing,'on') || strcmp(Drawing,'off'))
error('Please input parameters as specified Drawing. For details, please type help Mean_Filter')
end
%% Function core
if Method == 1
if isempty(Input1)
Input1 = 1:length(Input2);
end
New = zeros(size(Input1,1),size(Input1,2));
arm = floor(Window/2);
area = arm+1:length(Input1)-arm;
if strcmp(Edge_Check,'none') % No edge treatment
for i = 1:arm
New(1,i) = Input2(1,i);
end
for i = length(Input1)-arm+1:length(Input1)
New(1,i) = Input2(1,i);
end
end
%%%%%%%%%%%%%%%%%%%
% Edge treatments can be added later here
%%%%%%%%%%%%%%%%%%%
for i = area % core
M = Input2(1,i-arm:i+arm);
New(1,i) = mean(M);
end
Output1 = Input1; % output
Output2 = New;
if strcmp(Drawing,'on') % Detect whether to draw
figure
subplot(121)
plot(Input1,Input2,'b-','LineWidth',1)
grid on
title('Original input')
subplot(122)
plot(Output1,Output2,'b-','LineWidth',1)
grid on
title('After arithmetic mean filtering')
end
end
if Method == 2
New = zeros(size(Input1,1),size(Input1,2));
if strcmp(Window_type,'square') || strcmp(Window_type,'rectangle') || strcmp(Window_type,'cross')
if size(Window,2) == 1
r_arm = floor(Window/2);
c_arm = r_arm;
elseif size(Window,2) == 2
r_arm = floor(Window(1,2)/2); % Longitudinal arm length
c_arm = floor(Window(1,1)/2); % Cross arm length
end
end
r_area = r_arm+1:r_length-r_arm;
c_area = c_arm+1:c_length-c_arm;
if strcmp(Edge_Check,'none') % No edge treatment
for i = 1:r_arm
New(i,:) = Input1(i,:);
end
for i = r_length-r_arm+1:r_length
New(i,:) = Input1(i,:);
end
for j = 1:c_arm
New(:,j) = Input1(:,j);
end
for j = c_length-c_arm+1:c_length
New(:,j) = Input1(:,j);
end
end
%%%%%%%%%%%%%%%%%%%
% Edge treatments can be added later here
%%%%%%%%%%%%%%%%%%%
if strcmp(Window_type,'square') || strcmp(Window_type,'rectangle') % core
for i = r_area
for j = c_area
M = Input1(i-r_arm:i+r_arm,j-c_arm:j+c_arm);
New(i,j) = mean(mean(M));
end
end
elseif strcmp(Window_type,'cross')
for i = r_area
for j = c_area
M = [Input1(i-r_arm:i+r_arm,j)',Input1(i,j-c_arm:j+c_arm)];
New(i,j) = mean(mean(M));
end
end
end
Output1 = New; % output
Output1 = uint8(Output1);
Output2 = [];
if strcmp(Drawing,'on') % Detect whether to draw
subplot(121)
imshow(Input1)
title('Original picture')
subplot(122)
imshow(Output1)
title('Arithmetic mean filtered image')
end
end
if Method == 3
New = zeros(r_length,c_length,3);
if strcmp(Window_type,'square') || strcmp(Window_type,'rectangle') || strcmp(Window_type,'cross')
if size(Window,2) == 1
if size(Window,1) == 1
R_r_arm = floor(Window/2); % Red longitudinal arm length
R_c_arm = R_r_arm; % Red cross arm length
G_r_arm = floor(Window/2); % Green longitudinal arm length
G_c_arm = G_r_arm; % Green cross arm length
B_r_arm = floor(Window/2); % Blue longitudinal arm length
B_c_arm = B_r_arm; % Blue cross arm length
elseif size(Window,1) == 3
R_r_arm = floor(Window(1,1)/2); % Red longitudinal arm length
R_c_arm = R_r_arm; % Red cross arm length
G_r_arm = floor(Window(2,1)/2); % Green longitudinal arm length
G_c_arm = G_r_arm; % Green cross arm length
B_r_arm = floor(Window(3,1)/2); % Blue longitudinal arm length
B_c_arm = B_r_arm; % Blue cross arm length
end
elseif size(Window,2) == 2
if size(Window,1) == 1
R_r_arm = floor(Window(1,2)/2); % Red longitudinal arm length
R_c_arm = floor(Window(1,1)/2); % Red cross arm length
G_r_arm = floor(Window(1,2)/2); % Green longitudinal arm length
G_c_arm = floor(Window(1,1)/2); % Green cross arm length
B_r_arm = floor(Window(1,2)/2); % Blue longitudinal arm length
B_c_arm = floor(Window(1,1)/2); % Blue cross arm length
elseif size(Window,1) == 3
R_r_arm = floor(Window(1,2)/2); % Red longitudinal arm length
R_c_arm = floor(Window(1,1)/2); % Red cross arm length
G_r_arm = floor(Window(2,2)/2); % Green longitudinal arm length
G_c_arm = floor(Window(2,1)/2); % Green cross arm length
B_r_arm = floor(Window(3,2)/2); % Blue longitudinal arm length
B_c_arm = floor(Window(3,1)/2); % Blue cross arm length
end
end
end
R_r_area = R_r_arm+1:r_length-R_r_arm;
R_c_area = R_c_arm+1:c_length-R_c_arm;
G_r_area = G_r_arm+1:r_length-G_r_arm;
G_c_area = G_c_arm+1:c_length-G_c_arm;
B_r_area = B_r_arm+1:r_length-B_r_arm;
B_c_area = B_c_arm+1:c_length-B_c_arm;
if strcmp(Edge_Check,'none') % No edge treatment
for k = 1:3
if k == 1
r_arm = R_r_arm;
c_arm = R_c_arm;
elseif k == 2
r_arm = G_r_arm;
c_arm = G_c_arm;
else
r_arm = B_r_arm;
c_arm = B_c_arm;
end
for i = 1:r_arm
New(i,:,k) = Input1(i,:,k);
end
for i = r_length-r_arm+1:r_length
New(i,:,k) = Input1(i,:,k);
end
for j = 1:c_arm
New(:,j,k) = Input1(:,j,k);
end
for j = c_length-c_arm+1:c_length
New(:,j,k) = Input1(:,j,k);
end
end
end
%%%%%%%%%%%%%%%%%%%
% Edge treatments can be added later here
%%%%%%%%%%%%%%%%%%%
for k = 1:3 % core
if k == 1
r_arm = R_r_arm;
c_arm = R_c_arm;
r_area = R_r_area;
c_area = R_c_area;
elseif k == 2
r_arm = G_r_arm;
c_arm = G_c_arm;
r_area = G_r_area;
c_area = G_c_area;
else
r_arm = B_r_arm;
c_arm = B_c_arm;
r_area = B_r_area;
c_area = B_c_area;
end
if strcmp(Window_type,'square') || strcmp(Window_type,'rectangle') % core
for i = r_area
for j = c_area
M = Input1(i-r_arm:i+r_arm,j-c_arm:j+c_arm,k);
New(i,j,k) = mean(mean(M));
end
end
elseif strcmp(Window_type,'cross')
for i = r_area
for j = c_area
M = [Input1(i-r_arm:i+r_arm,j,k)',Input1(i,j-c_arm:j+c_arm,k)];
New(i,j,k) = mean(mean(M));
end
end
end
Output1 = New; % output
Output1 = uint8(Output1);
Output2 = [];
if strcmp(Drawing,'on') % Detect whether to draw
subplot(121)
imshow(Input1)
title('Original picture')
subplot(122)
imshow(Output1)
title('Arithmetic mean filtered image')
end
end
end
end
clc,clear all,close all
t = imread('D:\Huawei Share\OneHop\IMG_20210912_122924.jpg');
t = imnoise(t,'salt & pepper',0.1); % The addition density is 0.1 Salt and pepper noise
[ans1,ans2] = Mean_Filter(3,t,[],[3,3;3,5;3,3],'rectangle','none','on'); % 3*3 Square window median filter

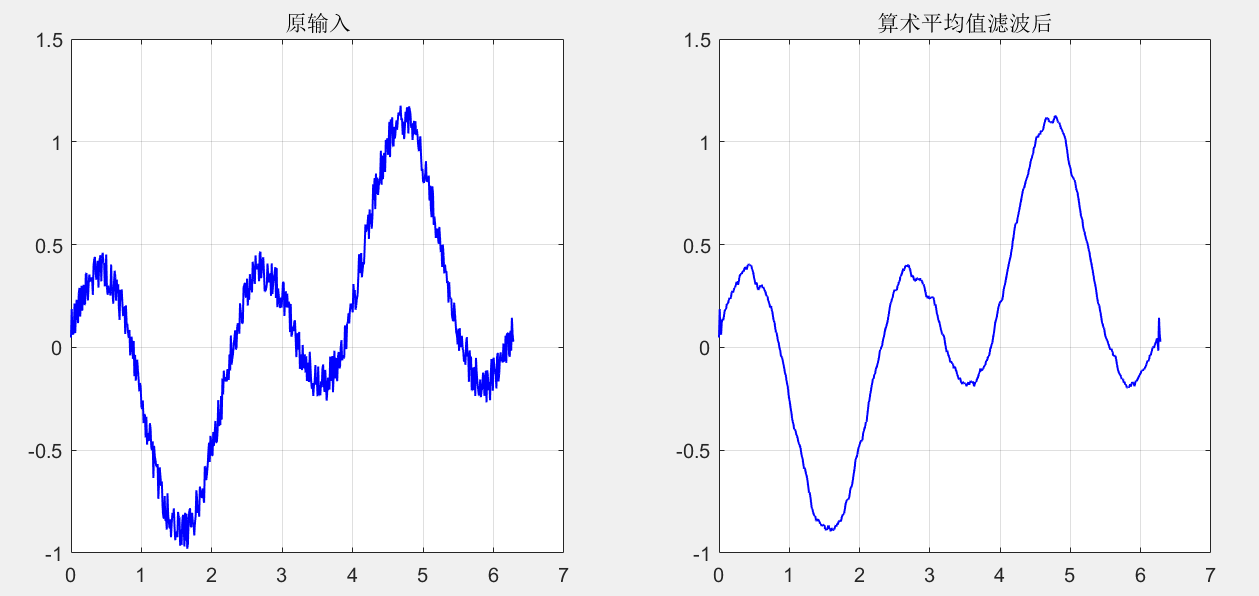
clc,clear all,close all x = 0:0.01:2*pi; y = sin(x).*cos(2*x)+0.2*rand(1,length(x)); [ans1,ans2] = Mean_Filter(1,x,y,9,'default','none','on'); [ans1,ans2] = Median_Filter(1,ans1,ans2,9,'default','none','on');
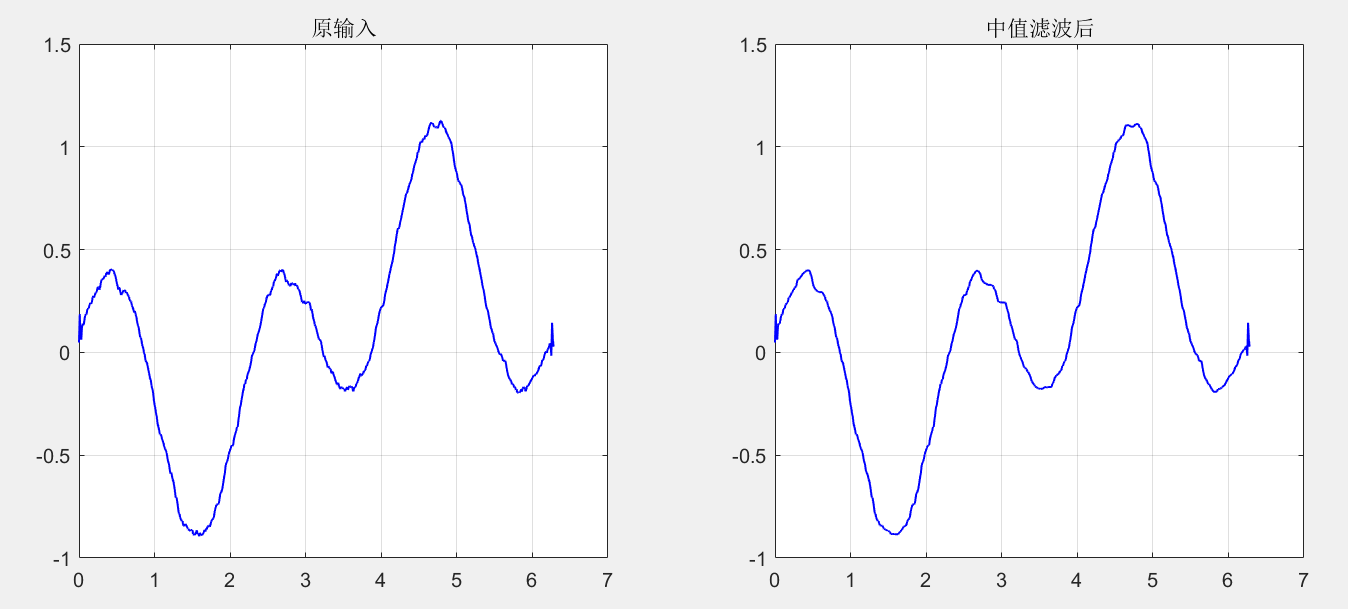
Author: K2SO4 potassium (Central China Normal University)
Cao Lixue, Zhang Pengchao. Computer control technology [M]. Xi'an: Xi'an University of Electronic Science and Technology Press. 2012 ↩︎
Cao Lixue, Zhang Pengchao. Computer control technology [M]. Xi'an: Xi'an University of Electronic Science and Technology Press. 2012 ↩︎
Salt and pepper noise - Sogou encyclopedia [EB/OL], doi: https://baike.sogou.com/v10913627.htm?fromTitle=%E6%A4%92%E7%9B%90%E5%99%AA%E5%A3%B0]
↩︎