--neozng1@hnu.edu.cn
1. Backbone
As a network focusing on edge platform deployment, especially for CPU devices, NanoDet naturally chose to use a lightweight backbone network with deep separable convolution.
Here we mainly introduce the default Backbone: GhostNet , this is a lightweight backbone network proposed by Huawei. For details about GhostNet, please stamp: placeholder . This module provides pre training weight download, and encapsulates the structure into a class.
ghostnet. The file py is placed under nanodet/model/backbone in the warehouse.
1.0. _make_divisible()
# _ make_divisible() is a function for rounding to ensure that the input and output of ghost module can be divided by the number of test paper # This is because of NN Conv2d requires that the groups parameter must be divisible by the input and output. For details, please refer to the data related to deep separable convolution def _make_divisible(v, divisor, min_value=None): """ This function is taken from the original tf repo. It ensures that all layers have a channel number that is divisible by 8 It can be seen here: https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py """ if min_value is None: min_value = divisor new_v = max(min_value, int(v + divisor / 2) // divisor * divisor) # Make sure that round down does not go down by more than 10%. if new_v < 0.9 * v: new_v += divisor return new_v
1.1. SqueezeExcite
class SqueezeExcite(nn.Module): def __init__( self, in_chs, se_ratio=0.25, reduced_base_chs=None, activation="ReLU", gate_fn=hard_sigmoid, divisor=4, **_ ): super(SqueezeExcite, self).__init__() self.gate_fn = gate_fn reduced_chs = _make_divisible((reduced_base_chs or in_chs) * se_ratio, divisor) # Global average pooling of channel wise self.avg_pool = nn.AdaptiveAvgPool2d(1) # 1x1 convolution to obtain a one-dimensional vector with smaller dimension self.conv_reduce = nn.Conv2d(in_chs, reduced_chs, 1, bias=True) # Send to the activation layer self.act1 = act_layers(activation) # Add a 1x1 conv to restore the output length back to the number of channels self.conv_expand = nn.Conv2d(reduced_chs, in_chs, 1, bias=True) def forward(self, x): x_se = self.avg_pool(x) x_se = self.conv_reduce(x_se) x_se = self.act1(x_se) x_se = self.conv_expand(x_se) # Multiply the weight just obtained by the original input x = x * self.gate_fn(x_se) return x
This module comes from SENet , please stamp the blog where the author introduced vision attention: Attention mechanism in CV_ Blog of HNU leaping deer team - CSDN blog . Use additional global pooling + FC + channel wise multiply to build SE branches, which can be used to capture the correlation between channels and give greater weight to important channels.
1.2. ConvBnAct
class ConvBnAct(nn.Module): def __init__(self, in_chs, out_chs, kernel_size, stride=1, activation="ReLU"): super(ConvBnAct, self).__init__() self.conv = nn.Conv2d( in_chs, out_chs, kernel_size, stride, kernel_size // 2, bias=False ) self.bn1 = nn.BatchNorm2d(out_chs) self.act1 = act_layers(activation) def forward(self, x): x = self.conv(x) x = self.bn1(x) x = self.act1(x) return x
This is actually the superposition of convolution, batch normalization and activation functions. These three structures are almost the standard configuration of the constituent units of the current deep network. They are written into a module to facilitate multiple calls later.
1.3.GhostModule
class GhostModule(nn.Module): def __init__( self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, activation="ReLU" ): super(GhostModule, self).__init__() self.oup = oup # Determine the proportion of feature layer reduction, init_channels are derived from standard convolution operations init_channels = math.ceil(oup / ratio) # new_channels are obtained by using cheap operations new_channels = init_channels * (ratio - 1) # Standard conv BN activation layer. Note that conv is 1x1 convolution of point wise conv self.primary_conv = nn.Sequential( nn.Conv2d( inp, init_channels, kernel_size, stride, kernel_size // 2, bias=False ), nn.BatchNorm2d(init_channels), act_layers(activation) if activation else nn.Sequential(), ) # The core of ghostNet is to generate similar feature maps with cheap linear operation # The key is that the number of groups is init_channels, each init_ Each channel corresponds to a layer of conv # The number of output channels is twice the input ratio-1, and each input channel will have a ratio-1 group of parameters self.cheap_operation = nn.Sequential( nn.Conv2d( init_channels, new_channels, dw_size, 1, dw_size // 2, groups=init_channels, bias=False, ), # BN and AC operation nn.BatchNorm2d(new_channels), act_layers(activation) if activation else nn.Sequential(), ) def forward(self, x): x1 = self.primary_conv(x) x2 = self.cheap_operation(x1) # new_channel and init_channel is a parallel relationship, which is spliced together to form a new output out = torch.cat([x1, x2], dim=1) return out
This module is the key to GhostNet, Before understanding the so-called "cheap operation" of GhostNet, i.e. heap_operation, you need to know the concepts of group conv and depth wise separable conv. first, perform standard convolution on the input of the previous feature layer to generate the feature of init_channels; then group convolute this feature, and obtain the same number of groups as the input number of channels (each channel corresponds to a separate convolution kernel), which can reduce the amount of parameters and operations as much as possible, and the overhead is very small
1.4. GhostBottleneck
GhostBottleneck is the basic architecture of GhostNet. GhostNet is formed by stacking several ghostbottlenecks. For bottleneck with strike = 2, a deep separable convolution is added between two ghost modules as a connection.
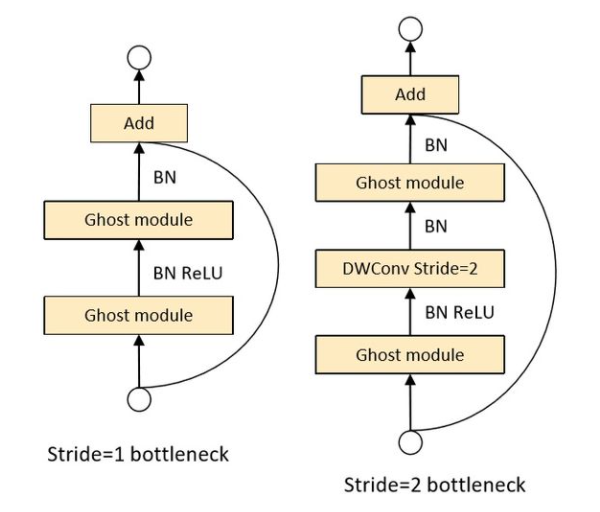
The structure of ghost bottle nect is divided into stripe = 1 in stage and stripe = 2 between stages
class GhostBottleneck(nn.Module): """Ghost bottleneck w/ optional SE""" def __init__( self, in_chs, mid_chs, out_chs, dw_kernel_size=3, stride=1, activation="ReLU", se_ratio=0.0, ): super(GhostBottleneck, self).__init__() # You can choose whether to add SE module has_se = se_ratio is not None and se_ratio > 0.0 self.stride = stride # Point-wise expansion # The first ghost will have a larger mid_chs is the number of output channels self.ghost1 = GhostModule(in_chs, mid_chs, activation=activation) # Depth-wise convolution # For the version with stripe = 2 (or you choose to add a larger stripe), DW convolution is added between the two ghostmodules if self.stride > 1: self.conv_dw = nn.Conv2d( mid_chs, mid_chs, dw_kernel_size, stride=stride, padding=(dw_kernel_size - 1) // 2, groups=mid_chs, bias=False, ) self.bn_dw = nn.BatchNorm2d(mid_chs) # Squeeze-and-excitation if has_se: self.se = SqueezeExcite(mid_chs, se_ratio=se_ratio) else: self.se = None # Point-wise linear projection # The final output does not add an activation function layer and uses a smaller out_chs to match the number of channels connected by short cut self.ghost2 = GhostModule(mid_chs, out_chs, activation=None) # shortcut # The last hop connection, if in_chs equals out_chs executes element wise add directly if in_chs == out_chs and self.stride == 1: self.shortcut = nn.Sequential() # If not, the depth separable convolution is used to align the size of the feature map else: self.shortcut = nn.Sequential( nn.Conv2d( in_chs, in_chs, dw_kernel_size, stride=stride, padding=(dw_kernel_size - 1) // 2, groups=in_chs, bias=False, ), nn.BatchNorm2d(in_chs), nn.Conv2d(in_chs, out_chs, 1, stride=1, padding=0, bias=False), nn.BatchNorm2d(out_chs), ) def forward(self, x): # Keep the identity feature and connect later residual = x # 1st ghost bottleneck x = self.ghost1(x) # If stripe > 1, add depth wise revolution if self.stride > 1: x = self.conv_dw(x) x = self.bn_dw(x) # Squeeze-and-excitation if self.se is not None: x = self.se(x) # 2nd ghost bottleneck x = self.ghost2(x) x += self.shortcut(residual) return x
The convolution used to generate complex features in ghost module is 1x1 point wise conv. for bottleneck with strike = 2, there is another DW with strike = 2. Then the former and the latter can be regarded as forming a group of deep separable convolutions, but the operation of ghost module to generate ghost feature greatly reduces the amount of parameters and computation. If has is enabled_ Se option, an SE branch will be added between two ghost modules.
1.5. GhostNet
After explaining the basic modules, we can use the above GhostBottleneck to build GhostNet:
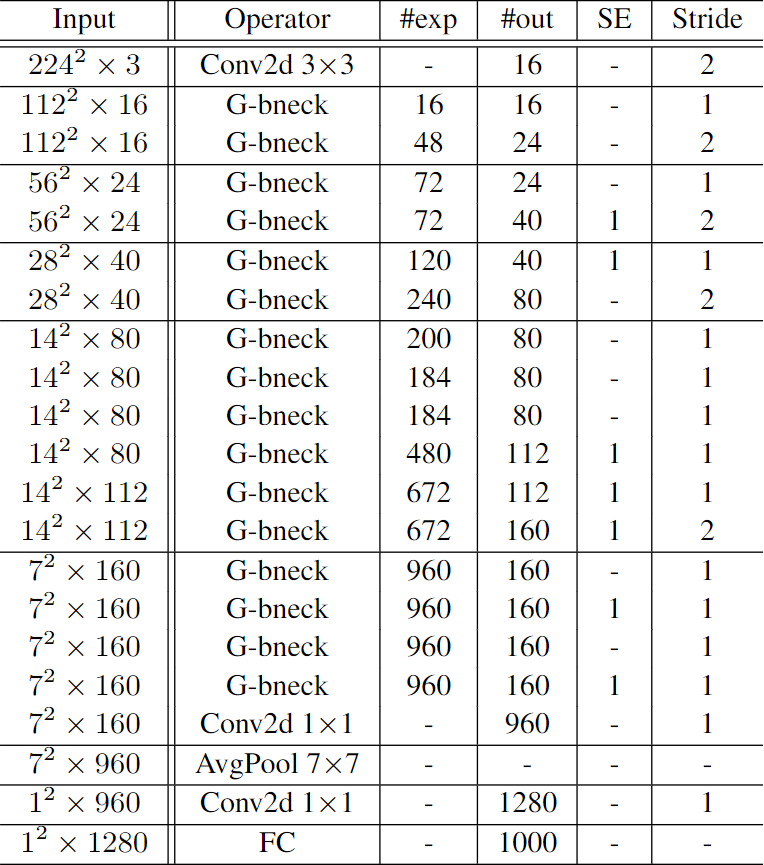
The structure of the whole backbone in the original GhostNet, #exp is the multiple of the channel expansion in bottleneck, #out is the number of output channels of the current layer
#exp represents the multiple of channel expansion after passing through the first ghost module in the bottleneck. The number of channels will then be reduced to the same as the first input in the bottleneck in the second ghost module of the same bottleneck for res connection# out is the number of output channels. It can be found that the bottleneck with strike = 2 is used between two different stage s to change the size of the feature map.
In order to be used as a detection network, delete the FC last used for classification, and take the output of stage 4, 6 and 9 as the input of FPN. If you need to pursue speed, you can consider further reducing the number of layers of each stage or directly cutting down several stages.