Netty provides many preset codecs and processors for many, which can be used almost out of the box, reducing the time and energy spent on cumbersome affairs
Idle connections and timeouts
Detecting idle connections and timeout is very important for releasing resources. Netty specifically provides several ChannelHandler implementations for it
| name | describe |
|---|---|
| IdleStateHandler | When the connection is idle for too long, an IdleStateEvent event will be triggered. Then, you can handle the IdleStateEvent by overriding the userEventTriggered() method in ChannelInboundHandler |
| ReadTimeoutHandler | If no inbound data is received within the specified time interval, a ReadTimeoutException is thrown and the corresponding Channel is closed. The ReadTimeoutException can be detected by overriding the exceptionguess () method in your ChannelHandler |
| WriteTimeoutHandler | If no outbound data is written within the specified time interval, a WriteTimeoutException will be thrown and the corresponding Channel will be closed. The WriteTimeoutException can be detected by overriding the exceptionguess () method in your ChannelHandler |
The following code shows that when using the usual method of sending heartbeat messages to remote nodes, if no data is received or sent within 60 seconds, we will be notified. If there is no response, the connection will be closed
public class IdleStateHandlerInitializer extends ChannelInitializer<Channel> {
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
// IdleStateHandler will send an IdleStateEvent event when triggered
pipeline.addLast(new IdleStateHandler(0, 0, 60, TimeUnit.SECONDS));
// Add a HeartbeatHandler to the ChannelPipeline
pipeline.addLast(new HeartbeatHandler());
}
public static final class HeartbeatHandler extends SimpleChannelInboundHandler {
// Heartbeat message sent to remote node
private static final ByteBuf HEARTBEAT_SEQUENCE = Unpooled
.unreleasableBuffer(Unpooled.copiedBuffer("HEARTBEAT", CharsetUtil.ISO_8859_1));
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
if (evt instanceof IdleStateEvent) {
// Send a heartbeat message and close the connection when sending fails
ctx.writeAndFlush(HEARTBEAT_SEQUENCE.duplicate())
.addListener(ChannelFutureListener.CLOSE_ON_FAILURE);
} else {
super.userEventTriggered(ctx, evt);
}
}
@Override
protected void messageReceived(ChannelHandlerContext ctx, Object msg) throws Exception {
}
}
}
Decoding separator based protocols
The separator based message protocol uses defined characters to mark the beginning or end of a message or message segment. The decoders listed in the following table can help you define a custom decoder that can extract frames separated by any tag sequence
| name | describe |
|---|---|
| DelimiterBasedFrameDecoder | Frames are extracted using a separator provided by the user |
| LineBasedFrameDecoder | Frames are separated by line endings (\ n or \ r\n) |
The following code shows how to use LineBasedFrameDecoder to process frames separated by line endings
public class LineBasedHandlerInitializer extends ChannelInitializer<Channel> {
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
// The LineBasedFrameDecoder forwards the extracted frame to the next ChannelInboundHandler
pipeline.addLast(new LineBasedFrameDecoder(64 * 1024));
// Add FrameHandler to receive frames
pipeline.addLast(new FrameHandler());
}
public static final class FrameHandler extends SimpleChannelInboundHandler<ByteBuf> {
@Override
protected void messageReceived(ChannelHandlerContext ctx, ByteBuf msg) throws Exception {
// do something
}
}
}
If you also use delimiters other than line endings to separate frames, you can also use DelimiterBasedFrameDecoder, which only needs to specify a specific sequence of delimiters to its constructor
As an example, we will use the following protocol specification:
- The incoming data stream is a series of frames, each separated by a newline \ n character
- Each frame consists of a series of elements, each separated by a single space character
- The content of a frame represents a command, which is defined as a command name followed by a variable number of parameters
Based on this protocol, our custom decoder will define the following classes:
- Cmd -- store the command of frame in ByteBuf, one for name and the other for parameter
- CmdDecoder -- get a line of string from the overridden decode() method and build a Cmd instance from its contents
- CmdHandler -- get the decoded Cmd object from the CmdDecoder and do some processing on it
public class CmdHandlerInitializer extends ChannelInitializer<Channel> {
static final byte SPACE = (byte) ' ';
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new CmdDecoder(64 * 1024));
pipeline.addLast(new CmdHandler());
}
/**
* Cmd POJO
*/
public static final class Cmd {
private final ByteBuf name;
private final ByteBuf args;
public Cmd(ByteBuf name, ByteBuf args) {
this.name = name;
this.args = args;
}
public ByteBuf getArgs() {
return args;
}
public ByteBuf getName() {
return name;
}
}
public static final class CmdDecoder extends LineBasedFrameDecoder {
public CmdDecoder(int maxLength) {
super(maxLength);
}
@Override
protected Object decode(ChannelHandlerContext ctx, ByteBuf buffer) throws Exception {
// Extract frames separated by a sequence of line endings from ByteBuf
ByteBuf frame = (ByteBuf) super.decode(ctx, buffer);
// If there is no frame in the input, null is returned
if (frame == null) {
return null;
}
// Find the index of the first space character, preceded by the command name and followed by the parameter
int index = frame.indexOf(frame.readerIndex(), frame.writerIndex(), SPACE);
// Create a new Cmd object using the slice containing the command name and parameters
return new Cmd(frame.slice(frame.readerIndex(), index), frame.slice(index + 1, frame.writerIndex()));
}
}
public static final class CmdHandler extends SimpleChannelInboundHandler<Cmd> {
@Override
protected void messageReceived(ChannelHandlerContext ctx, Cmd msg) throws Exception {
// Handle Cmd objects passing through ChannelPipeline
}
}
}
Length based protocol
The length based protocol defines the frame by encoding its length into the header of the frame, rather than marking its end with a special separator. The following table lists the two decoders provided by Netty to handle this type of protocol
| name | describe |
|---|---|
| FixedLengthFrameDecoder | Extract the fixed length frame specified when calling the constructor |
| LengthFieldBasedFrameDecoder | The frame is extracted according to the length value in the frame header: the offset and length of this field are specified in the constructor |
You often encounter a protocol in which the frame size encoded into the message header is not a fixed value. In order to deal with this variable length frame, you can use the LengthFieldBasedFrameDecoder, which will determine the frame length from the header field, and then extract the specified number of bytes from the data stream
The following figure shows an example in which the offset of the length field in the frame is 0 and the length is 2 bytes
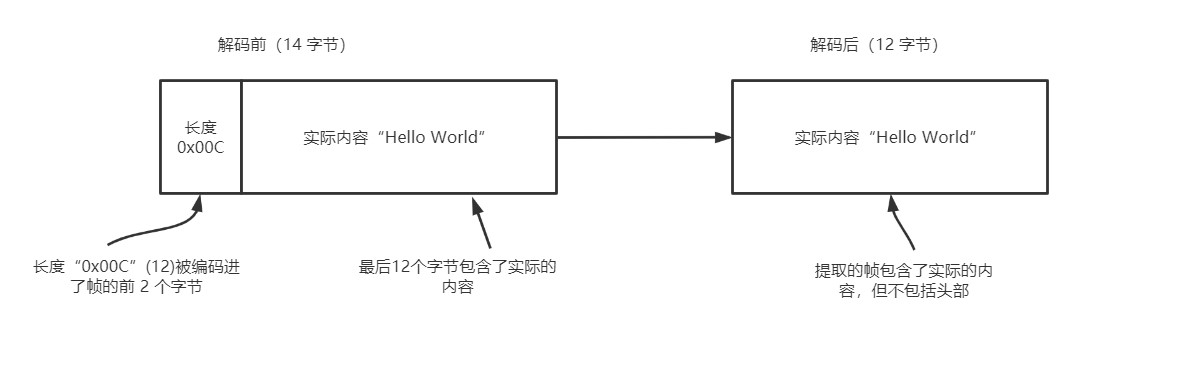
The following code shows how to use the constructors whose three constructors are maxFrameLength, lengthFieldOffser and lengthFieldLength. In this scenario, the length of the frame is encoded into the first 8 bytes at the beginning of the frame
public class LengthBasedInitializer extends ChannelInitializer<Channel> {
/**
* Use the LengthFieldBasedFrameDecoder to decode the message that encodes the frame length into the first 8 bytes at the beginning of the frame
*/
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new LengthFieldBasedFrameDecoder(64 * 1024, 0, 8));
pipeline.addLast(new FrameHandler());
}
public static final class FrameHandler extends SimpleChannelInboundHandler<ByteBuf> {
@Override
protected void messageReceived(ChannelHandlerContext ctx, ByteBuf msg) throws Exception {
// do something
}
}
}
Write large data
Because of the possibility of network saturation, how to write large blocks of data efficiently in asynchronous framework is a special problem. Since the write operation is non blocking, even if all data is not written out, the write operation will return and notify ChannelFuture when it is completed. When this happens, there is a risk of running out of memory if you keep writing. Therefore, when writing large data, it is necessary to consider that the connection of the remote node is slow, which will lead to the delay of memory release. Let's consider writing out the contents of a file to the network
NIO's zero copy feature eliminates the copying process of moving the contents of files from the file system to the network stack. All this happens in the core of Netty, so what the application needs to do is to use an implementation of the FileRegion interface
The following code shows how to create a DefaultFileRegion from FileInputStream and write it to the Channel
// Create a FileInputStream
leInputStream in = new FileInputStream(file);
// Create a new DefaultFileRegion with the full length of the file
FileRegion region = new DefaultFileRegion(in.getChannel(), 0, file.length());
// Send the DefaultFileRegion and register a ChannelFutureListener
channel.writeAndFlush(region).addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
// Processing failed
if(!future.isSuccess()) {
Throwable cause = future.cause();
// do something
}
}
});
This example is only applicable to the direct transmission of file content, and does not include any processing of data by the application. When you need to copy data from the file system to the user's memory, you can use ChunkedWriteHandler, which supports asynchronous writing of large data streams without causing a lot of memory consumption
The type parameter B in interface chunkedinput < b > is the type returned by the readChunk() method. Netty preset four implementations of the interface, as shown in the table, each representing an indefinite length data stream to be processed by ChunkedWriteHandler
| name | describe |
|---|---|
| ChunkedFile | Get data block by block from the file. Use it when your platform does not support zero copy or you need to convert data |
| ChunkedNioFile | It is similar to ChunkedFile, except that it uses FileChannel |
| ChunkedStream | Transfer content block by block from InputStream |
| ChunkedNioStream | Gradually transfer content from ReadableByteChannel |
The following code illustrates the usage of ChunkedStream, which is the most commonly used implementation in practice. The class shown uses a File and an SSLContext for instantiation. When the initChannel() method is called, it will initialize the Channel with the ChannelHandler chain shown
When the Channel becomes active, WriteStreamHandler will write the data from the file as ChunkedStream block by block
public class ChunkedWriteHandlerInitializer extends ChannelInitializer<Channel> {
private final File file;
private final SslContext sslContext;
public ChunkedWriteHandlerInitializer(File file, SslContext sslContext) {
this.file = file;
this.sslContext = sslContext;
}
@Override
protected void initChannel(Channel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new SslHandler(sslContext.newEngine(ch.alloc())));
// Add ChunkedWriteHandler to process data passed in as ChunkedInput
pipeline.addLast(new ChunkedWriteHandler());
// Once the connection is established, WriteStreamHandler starts writing file data
pipeline.addLast(new WriteStreamHandler());
}
public final class WriteStreamHandler extends SimpleChannelInboundHandler<Channel> {
/**
* When the connection is established, the channelActive() method uses ChunkedInput to write file data
*/
@Override
protected void messageReceived(ChannelHandlerContext ctx, Channel msg) throws Exception {
super.channelActive(ctx);
ctx.writeAndFlush(new ChunkedStream(new FileInputStream(file)));
}
}
}
Serialize data
JDK provides ObjectOutputStream and ObjectInputStream, which are used to serialize and deserialize the basic data types and graphs of POJO through the network. The API is not complex and can be applied to any implementation of Java io. The object of the serializable interface. But its performance is not efficient. In this section, we will see how Netty implements serialization
1. JDK serialization
If your program must interact with remote nodes using ObjectOutputStream and ObjectInputStream, and considering compatibility, JDK serialization will be the right choice. The following table lists the serialization classes provided by Netty for interacting with JDK
| name | describe |
|---|---|
| CompatibleObjectDecoder | A decoder that interoperates with non Netty based remote nodes serialized using JDK |
| CompatibleObjectEncoder | An encoder that interoperates with non Netty based remote nodes serialized using JDK |
| ObjectDecoder | A decoder built on JDK serialization that uses custom serialization to decode |
| ObjectEncoder | An encoder built on JDK serialization that uses custom serialization to encode |
2. Protocol Buffers serialization
Protocol Buffers is an open source data exchange format developed by Google. It encodes and decodes structured data in a compact and efficient way, and can be used across multiple languages. The following table shows the implementation of ChannelHandler provided by Netty to support Protobuf
| name | describe |
|---|---|
| ProtobufDecoder | Decoding messages using Protobuf |
| ProtobufEncoder | Encoding messages using Protobuf |
| ProtobufVarint32FrameDecoder | The received ByteBuf fer is dynamically divided according to the Base 128 Varints integer length field value of Google protobuffer buffers in the message |
| ProtobufVarint32LengthFieldPrepender | The length field value of the base 128 variables integer of Google protobuffer buffers is appended before ByteBuf fer |