For a language, a sentence has infinite possibilities. The problem is that we can only analyze structure and meaning through limited procedures. Try to understand "language" as a mere collection of grammatical sentences. On the basis of this idea, a formula similar to word - > word and / or /... word is established, which is called recursive production. In theory, sentences can be expanded indefinitely.
Grammar
Custom Grammar
Writing is basically the same as the classification rules of the previous blog, and it is simpler, more intuitive, and can be compared with the previous one.
import nltk
from nltk import CFG
grammar = nltk.CFG.fromstring("""
S -> NP VP
VP -> V NP | V NP PP
PP -> P NP
V -> "saw" | "ate" | "walked"
NP -> "John" | "Mary" | "Bob" | Det N | Det N PP
Det -> "a" | "an" | "the" | "my"
N -> "man" | "dog" | "cat" | "telescope" | "park"
P -> "in" | "on" | "by" | "with"
""")
sent = 'Mary saw Bob'.split()
rd_parser = nltk.RecursiveDescentParser(grammar)
for i in rd_parser.parse(sent):
print(i)When defining grammar, NP - >'New York'should be written as NP - >'New_York', and the space of join should be replaced by.
Grammatical uses
Language can basically be said to be a combination of decorative structure and juxtaposition structure. For example, the following is constantly expanding:
1. he ran
2. he ran there
3. he saw it there
4. the bear saw the font in it
Obviously the normal sentence is the fourth sentence, if the above process is reversed from 4 - > 1. Ultimately, you get two elements. That is to say, the word sequence in a compound grammatical rule sentence can be replaced by a smaller sequence that does not lead to a sentence that does not conform to grammatical rules. The following two pictures show the replacement of the first representative word sequence. The second picture is drawn according to grammar rules. (Attached screenshot*2)
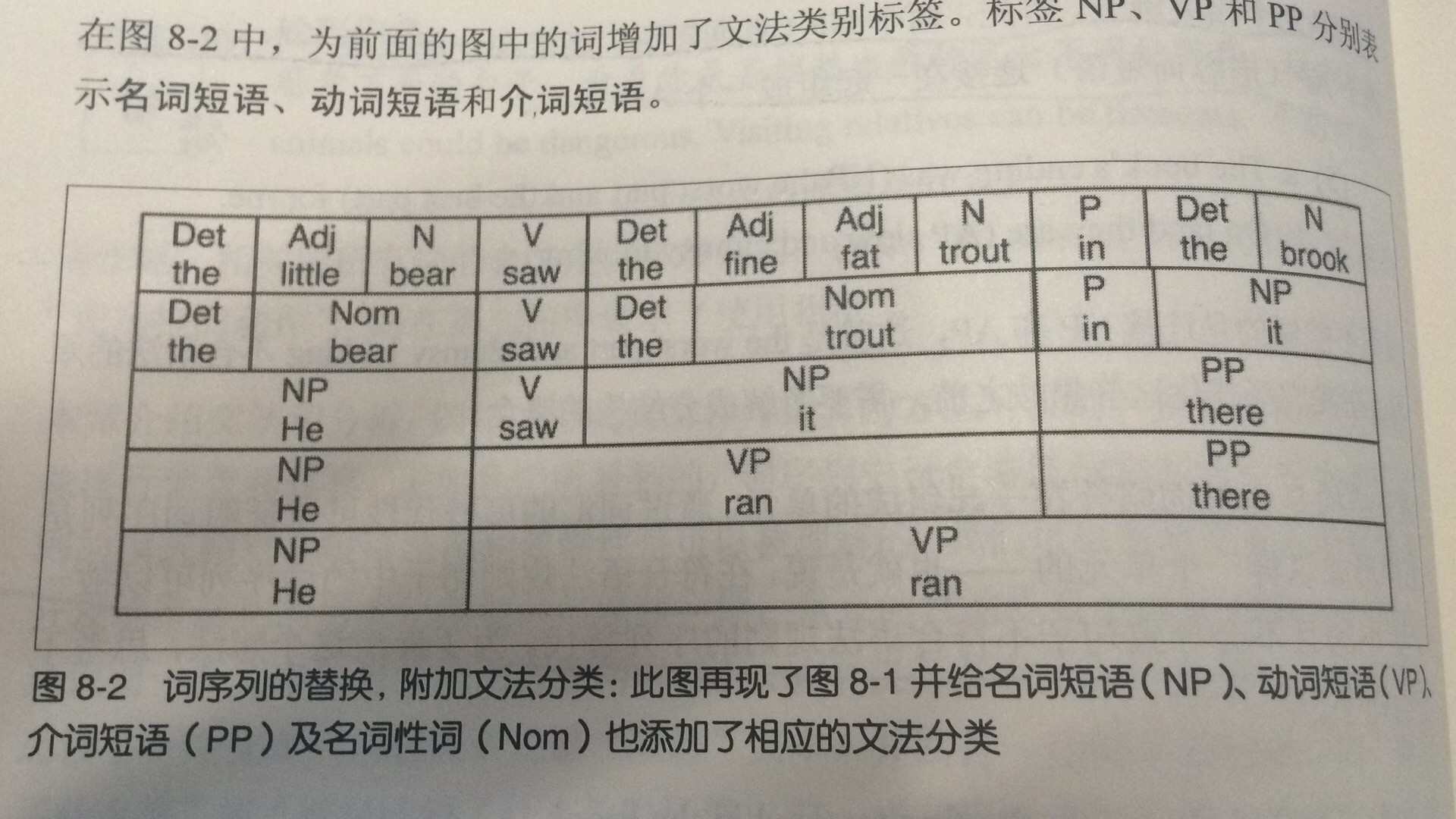
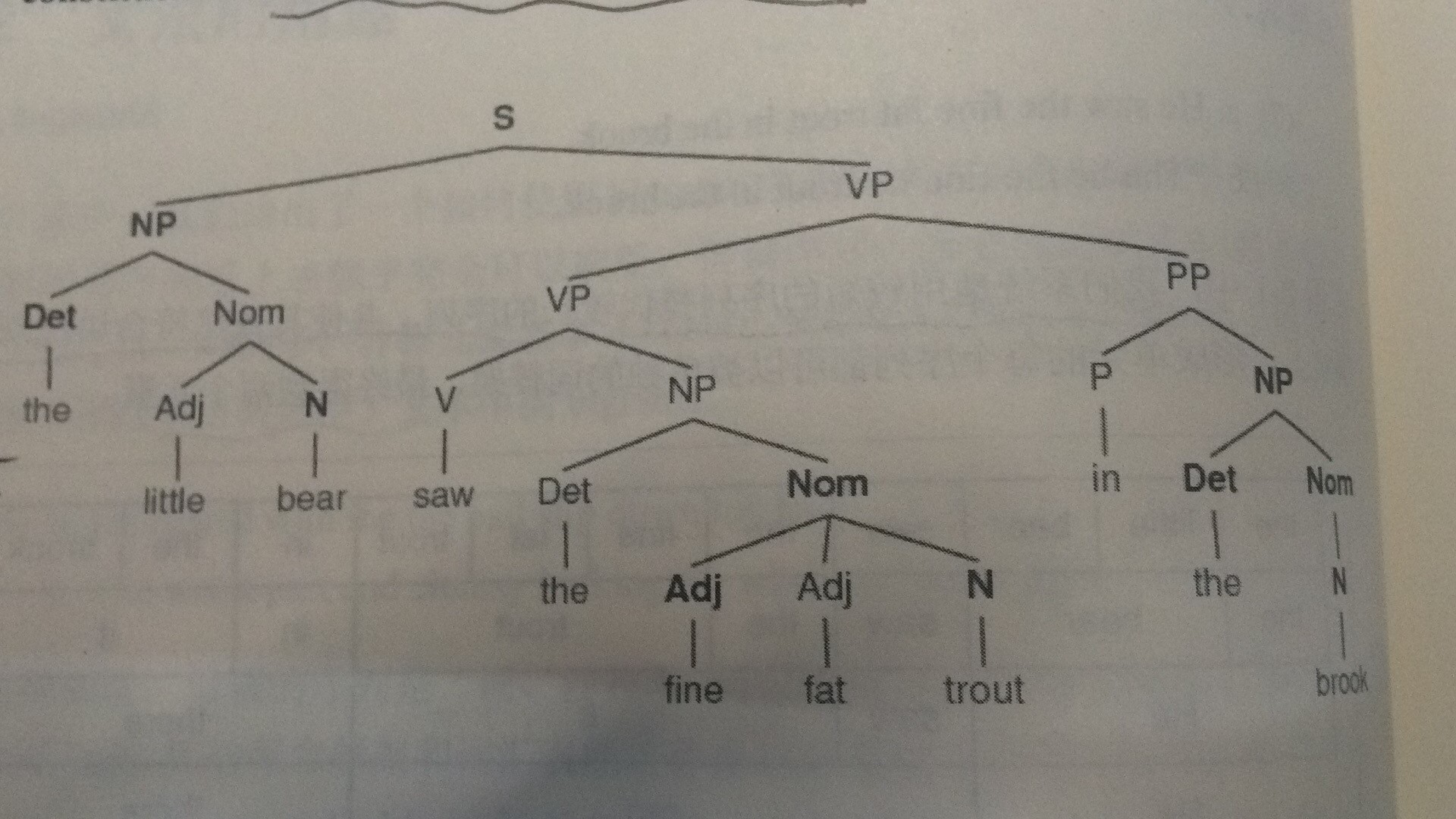
Developing Grammar
The following program shows how to use simple filters to find verbs with sentence complements.
from nltk.corpus import treebank
t = treebank.parsed_sents('wsj_0001.mrg')[0]
print(t) #View encapsulated grammar
def filter(tree):
child_nodes = [child.label() for child in tree if isinstance(child,nltk.Tree)]
return (tree.label() == 'VP') and ('S' in child_nodes)#Find out the verbs with sentence complements
[subtree for tree in treebank.parsed_sents() \
for subtree in tree.subtrees(filter)]Algorithms for Analyzing Grammar
- Decline Recursive Analysis: Top-down
- Transfer-Reduction Analysis: Bottom-up
- Left Corner Analysis: A Bottom-up Filtering Top-down Approach
- Chart Method: Dynamic Programming Technology
The following are the parsers corresponding to the first two analysis algorithms.
recursive descent parser
Three main shortcomings:
- Left recursive production: NP - > NP PP will fall into a dead cycle
- Waste time in dealing with words and structures that do not match sentences
- Overweight backtracking process will lose the calculated analysis and recalculate
import nltk
from nltk import CFG
grammar1 = nltk.CFG.fromstring("""
S -> NP VP
VP -> V NP | V NP PP
PP -> P NP
V -> "saw" | "ate" | "walked"
NP -> "John" | "Mary" | "Bob" | Det N | Det N PP
Det -> "a" | "an" | "the" | "my"
N -> "man" | "dog" | "cat" | "telescope" | "park"
P -> "in" | "on" | "by" | "with"
""")
rd_parser = nltk.RecursiveDescentParser(grammar1)
sent = 'Mary saw a dog'.split()
for t in rd_parser.parse(sent):
print(t)You can call nltk.app.rdparser() to see the analysis process
Shift-Reduction Parser
The parser repeatedly push es the next input word onto the stack as a shift operation. If n items in front of the stack match the n items on the right side of the expression, pop up the stack, and press the items on the left side of the production like the stack, it is called reduction operation.
Two shortcomings:
- Because of the particularity of the stack, only one kind of parsing can be found.
- There is no guarantee that an analysis will be found.
sr_parse = nltk.ShiftReduceParser(grammar1)
for t in sr_parse.parse(sent):
print(t)Feature-based grammar
How to control grammar more subtly and what structure to express it? Labels can be decomposed into dictionary-like structures and a series of values can be extracted as features.
Attributes and constraints
Let's start with an example by nltk.data.show_cfg('grammars/book_grammars/feat0.fcfg'):
% start S
# ###################
# Grammar Productions
# ###################
# S expansion productions
S -> NP[NUM=?n] VP[NUM=?n]
# NP expansion productions
NP[NUM=?n] -> N[NUM=?n]
NP[NUM=?n] -> PropN[NUM=?n]
NP[NUM=?n] -> Det[NUM=?n] N[NUM=?n]
NP[NUM=pl] -> N[NUM=pl]
# VP expansion productions
VP[TENSE=?t, NUM=?n] -> IV[TENSE=?t, NUM=?n]
VP[TENSE=?t, NUM=?n] -> TV[TENSE=?t, NUM=?n] NP
# ###################
# Lexical Productions
# ###################
Det[NUM=sg] -> 'this' | 'every'
Det[NUM=pl] -> 'these' | 'all'
Det -> 'the' | 'some' | 'several'
PropN[NUM=sg]-> 'Kim' | 'Jody'
N[NUM=sg] -> 'dog' | 'girl' | 'car' | 'child'
N[NUM=pl] -> 'dogs' | 'girls' | 'cars' | 'children'
IV[TENSE=pres, NUM=sg] -> 'disappears' | 'walks'
TV[TENSE=pres, NUM=sg] -> 'sees' | 'likes'
IV[TENSE=pres, NUM=pl] -> 'disappear' | 'walk'
TV[TENSE=pres, NUM=pl] -> 'see' | 'like'
IV[TENSE=past] -> 'disappeared' | 'walked'
TV[TENSE=past] -> 'saw' | 'liked'Similar to dictionary rules, NUM, TENSE are attributes, press, sg, pl are constraints. In this way, we can show sentences like'the some dogs'instead of'the some dogs'.
Among them, sg is singular, pl is plural, and? n is uncertain. Eigenvalues such as sg and pl are called atoms. Atoms can also be bool values. True and False are represented by + aux and - aux, respectively.
Processing feature structure
NLTK's feature structure is declared using the constructor FeatStuct(), and atomic eigenvalues can be strings or integers. Simple examples:
fs1 = nltk.FeatStruct("[TENSE = 'past',NUM = 'sg',AGR=[NUM='pl',GND = 'fem']]")
print(fs1)
print(fs1['NUM'])#It can be accessed like a dictionary.The printed discovery is in matrix form. In order to represent reentry in a matrix, a numeric prefix surrounded by parentheses, such as (1), can be added where the feature structure is shared. Later references to any of these structures will be used (1)
print(nltk.FeatStruct("""[NAME = 'Lee',ADDRESS=(1)[NUMBER=74,STREET='rue Pascal'],SPOUSE =[NAME='Kim',ADDRESS->(1)]]"""))The results are as follows:
[ ADDRESS = (1) [ NUMBER = 74 ] ] [ [ STREET = 'rue Pascal' ] ] [ ] [ NAME = 'Lee' ] [ ] [ SPOUSE = [ ADDRESS -> (1) ] ] [ [ NAME = 'Kim' ] ]
The result can be seen as a graph structure. If there is no num, it is a directed acyclic graph; if there is one, there is a ring. (with screenshots)
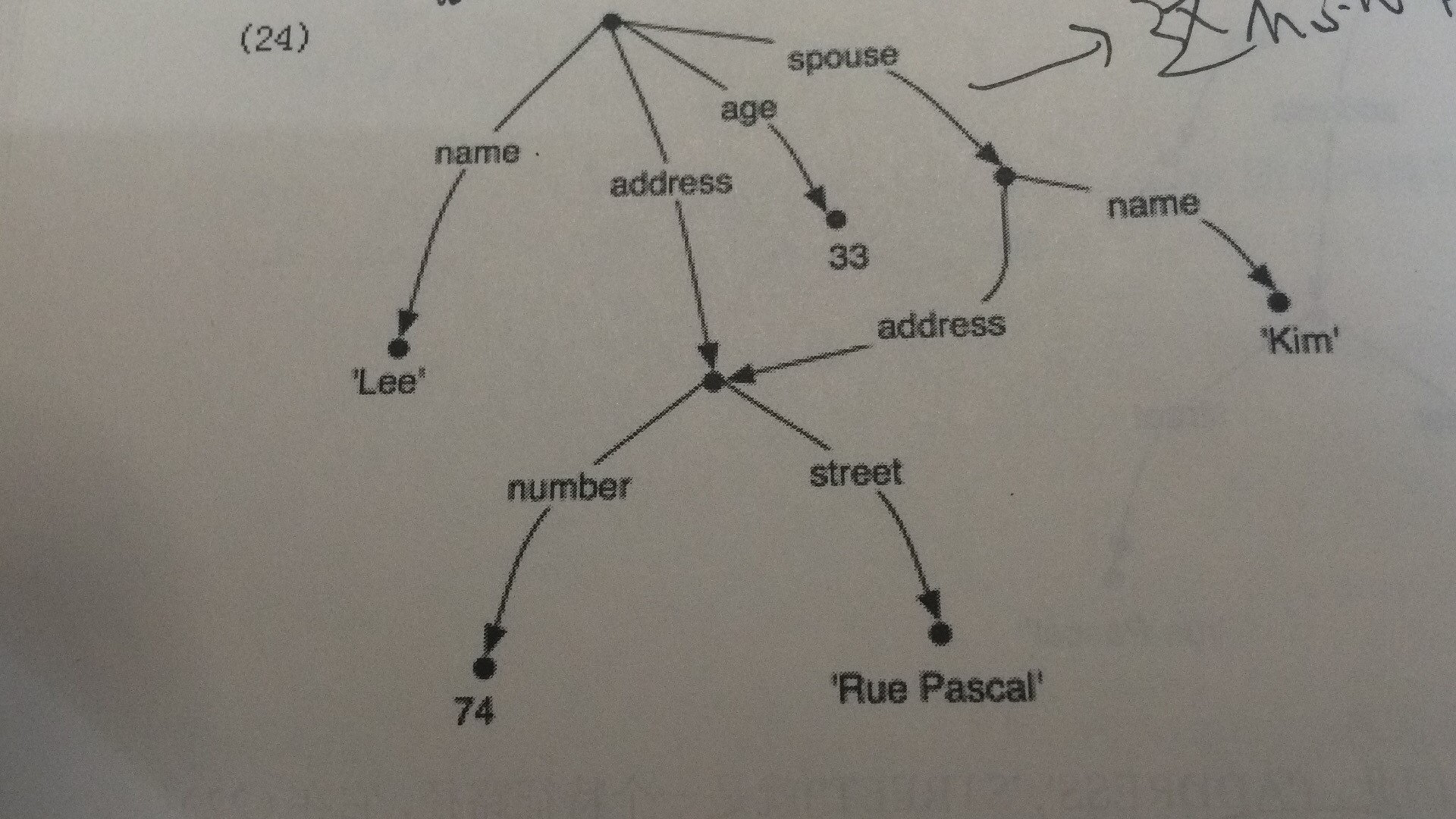
Inclusion and Unity
If there are two structures:
a.[num = 74]
b.[num = 74]
[street = 'BeiJing']So b contains a. Similar to set operations, this order is called inclusion.
Unification is to merge two structures, but if the same attribute has different values, it returns the None type.
fs1 = nltk.FeatStruct(NUMBER = 74)
fs2 = nltk.FeatStruct(City = 'BeiJint')
#fs2 = nltk.FeatStruct(NUMBER= 45)#Return to None
print(fs2.unify(fs1))summary
In NLP, simply put: grammar = grammar = lexicon + syntax.
It is a branch of linguistics that studies the twists and turns of "parts of speech" and "words" used according to definite usage, or other means of expressing interrelations, as well as the functions and relations of words in sentences. The rules of word formation, word formation and sentence formation are included.
Because different grammar frameworks differ in writing, it is necessary to view the requirements of relevant documents and libraries when constructing them. This aspect of programming, more on the basis of rules to study the relationship between words and parts of speech, and constantly improve grammar rules.
Welcome to further exchange the relevant content of this blog:
Blog Garden Address: http://www.cnblogs.com/AsuraDong/
CSDN address: http://blog.csdn.net/asuradong
Letters can also be sent for communication: xiaochiyijiu@163.com
Welcome to reprint, but please specify the origin: _____________