Original text: https://www.zlovezl.cn/book/ch10_solid_p1.html
As a popular programming mode, object-oriented is powerful, but it is also difficult to master. A beginner who has just come into contact with object-oriented, from being able to write some simple classes to being able to complete excellent object-oriented design alone, the whole process often takes months or even years.
In order to make object-oriented programming easier, many predecessors sorted their valuable experience into a large number of books and materials. The most famous of these books is design patterns: the basis of reusable object-oriented software published in 1994.
In design patterns, the four authors extracted and summarized a total of 23 classic design patterns from their own experience. These design patterns cover all aspects of object-oriented programming, such as object creation, behavior packaging, etc., and have great reference value and practicability.
However, it is strange that although the 23 design patterns in design patterns are very classic, we rarely hear Python developers discuss these patterns and rarely see them in the project code. Why? This is related to the dynamic nature of the python language.
Most of the design patterns in design patterns are created by the author in a static programming language in an object-oriented environment with many restrictions. But Python is different. Python is a dynamic programming language. It has a variety of flexible features, such as first-class function objects, "duck types", customizable data models and so on. Therefore, we rarely use Python to restore classic design patterns one by one. Instead, we almost always find a more Python appropriate representation for each design pattern.
For example, there is an example related to "Singleton mode" in section 9.3.4. In the sample code, I first use __ new__ Methods the classical single case design pattern is realized. But then, a module level global object meets the same requirements with less code.
# 1: Singleton mode
class AppConfig:
_instance = None
def __new__(cls):
if cls._instance is None:
inst = super().__new__(cls)
cls._instance = inst
return cls._instance
# 2: Global object
class AppConfig:
...
_config = AppConfig()
Since the design pattern is in Python, it can not bring us too much practical value as in other languages. How else can we learn object-oriented design? When we write object-oriented code, how to judge the advantages and disadvantages of different schemes? How to polish a better design?
SOLID design principles can answer the above questions.
In the object-oriented field, in addition to 23 classic design patterns, there are many classic design principles. Compared with specific design patterns, principles are usually more abstract, more applicable, and more suitable for integration into Python programming. Among all the design principles, SOLID is the most famous.
The prototype of SOLID principle first appeared in an article published by Robert C. Martin (Uncle Bob) in 2000. In this article entitled "Design Principles and Design Patterns", Uncle Bob created and sorted out several object-oriented design principles. In the subsequent Book Agile Software Development: principles, patterns and practices, Uncle Bob extracted the initials of these principles and formed the word SOLID to help him remember.
The five letters in SOLID represent five different design principles.
-
S: Single responsibility principle
-
O: Open – closed principle
-
50: L iskov Substitution Principle
-
1: I nterface aggregation principle
-
D: Dependency inversion principle
When writing object-oriented code, following these design principles can help you avoid common design traps and make it easier for you to write good code that is easy to expand. Conversely, if your code violates some of the principles, your design may have considerable room for improvement.
Next, we will learn the specific contents of these five design principles. We will actually apply the principles to Python code through some real cases.
Due to the large content of SOLID principle, I divided it into two chapters. In this chapter, we will learn the first two of these five principles:
-
S: Single responsibility principle
-
O: Open – closed principle
Let's start!
10.1 type annotation basis
In order to make the code more descriptive and better describe the characteristics of each SOLID principle, all the code in this chapter and the next chapter will use the type annotation feature of Python.
In Chapter 1, I briefly introduced Python's type hint function. In short, type annotation is a technology to add type descriptions to function parameters, return values, and any variables. Standardized annotation can greatly improve code readability.
For example, the following code does not have any type annotations:
class Duck:
"""Ducks
:param color: Duck color
"""
def __init__(self, color):
self.color = color
def quack(self):
print(f"Hi, I'm a {self.color} duck!")
def create_random_ducks(number):
"""Create a batch of random color ducks
:param number: Number of ducks to create
"""
ducks = []
for _ in number:
color = random.choice(['yellow', 'white', 'gray'])
ducks.append(Duck(color=color))
return ducksThe following is what the code looks like after adding type annotations:
from typing import List
class Duck:
def __init__(self, color: str):
self.color = color
def quack(self) -> None:
print(f"Hi, I'm a {self.color} duck!")
def create_random_ducks(number: int) -> List[Duck]:
ducks: List[Duck] = []
for _ in number:
color = random.choice(['yellow', 'white', 'gray'])
ducks.append(Duck(color=color))
return ducks| Type annotation of function parameters | |
| adopt → Annotate the return value with the type | |
| You can use typing Special objects for modules List To mark the specific types of list members. Note that [] Symbols, not () | |
| When you declare a variable, you can also annotate it with a type annotation | |
| Type annotations are optional and very free, such as here color There is no type annotation for variables |
typing It is the main module used in type annotation, except List In addition, there are many special objects related to types in this module, for example.
-
Dict: dictionary type, for example Dict[str, int] Represents a dictionary in which the key is a string and the value is an integer.
-
Callable: callable objects, such as Callable[[str, str], List[str]] Represents a callable object that accepts two strings as parameters and returns a string list.
-
TextIO: class file type using text protocol, corresponding to binary type: BinaryIO
-
Any: represents any type.
By default, you can treat the type annotation in Python as a special annotation to increase the readability of the code, because it is like annotation, which only improves the explicitness of the code and does not have any actual impact on the execution process of the program.
However, if static type checking tools are introduced, type annotations are no longer just annotations. It not only increases readability, but also has a positive impact on the correctness of the program. In section 13.1.5, I'll show you how to do this with mypy.
That's all for the introduction of type annotation. If you want to know more, you can check the "type annotation" section of the official Python document, which is quite detailed.
10.2 SRP: single responsibility principle
This chapter will illustrate the first two principles of SOLID through a specific case: SRP (single responsibility principle) and OCP (open close principle).
10.2.1 case: a simple Hacker News crawler
Hacker News (hereinafter referred to as HN) is a well-known foreign science and technology information site, which is very popular in the programmer circle. On the homepage of HN, you can read the current popular articles and participate in the discussion. At the same time, you can also submit new article links to the home page. The system will sort the articles according to the scoring algorithm, and the most popular articles will be ranked first. The screenshot of HN home page is shown in Figure 10-1.
I usually like to visit HN. I often go to it to find some popular articles. But every time I visit HN, I need to open my browser and find website bookmarks in my favorites. The steps are still very cumbersome - programmers are "lazy"!
In order to make browsing HN more convenient, I want to write a program to automatically obtain the title and links of the most popular items in the HN home page and save them in ordinary files. Isn't it beautiful that I can browse popular articles directly on the command line?
As a Python programmer, it's easy to write a small script. utilize requests,lxml Such as the powerful functions provided by the module, I wrote the program in less than half an hour.
import io
import sys
from typing import Iterable, TextIO
import requests
from lxml import etree
class Post:
"""HackerNew Entries on
:param title: title
:param link: link
:param points: Current score
:param comments_cnt: Number of comments
"""
def __init__(self, title: str, link: str, points: str, comments_cnt: str):
self.title = title
self.link = link
self.points = int(points)
self.comments_cnt = int(comments_cnt)
class HNTopPostsSpider:
"""Grab Hacker News Top Content entry
:param fp: The target file object that stores the crawl results
:param limit: Limit the number of entries. The default value is 5
"""
items_url = 'https://news.ycombinator.com/'
file_title = 'Top news on HN'
def __init__(self, fp: TextIO, limit: int = 5):
self.fp = fp
self.limit = limit
def write_to_file(self):
"""Convert in plain text Top Content write file"""
self.fp.write(f'# {self.file_title}\n\n')
for i, post in enumerate(self.fetch(), 1):
self.fp.write(f'> TOP {i}: {post.title}\n')
self.fp.write(f'> fraction:{post.points} Number of comments:{post.comments_cnt}\n')
self.fp.write(f'> Address:{post.link}\n')
self.fp.write('------\n')
def fetch(self) -> Iterable[Post]:
"""from HN Grab Top content
:return: Iterative Post object
"""
resp = requests.get(self.items_url)
# Using XPath, you can easily parse the content you need from the page. The following are the page parsing codes
# If you are not familiar with xpath, you can ignore the code and jump directly to the yield Post()
html = etree.HTML(resp.text)
items = html.xpath('//table[@class="itemlist"]/tr[@class="athing"]')
for item in items[: self.limit]:
node_title = item.xpath('./td[@class="title"]/a')[0]
node_detail = item.getnext()
points_text = node_detail.xpath('.//span[@class="score"]/text()')
comments_text = node_detail.xpath('.//td/a[last()]/text()')[0]
yield Post(
title=node_title.text,
link=node_title.get('href'),
# Items may not be rated
points=points_text[0].split()[0] if points_text else '0',
comments_cnt=comments_text.split()[0],
)
def main():
# with open('/tmp/hn_top5.txt') as fp:
# crawler = HNTopPostsSpider(fp)
# crawler.write_to_file()
# Because HNTopPostsSpider receives any file like object, we can pass sys.stdout in
# Realize the function of standard output printing to the console
crawler = HNTopPostsSpider(sys.stdout)
crawler.write_to_file()
if __name__ == '__main__':
main()| enumerate() Receive the second parameter, indicating counting from this number (0 by default) |
By executing this script, I can see the Top5 entry on the HN site on the command line:
$ python news_digester.py # Top news on HN > TOP 1: The auction that set off the race for AI supremacy > Score: 72 comments: 10 > Address: https://www.wired.com/story/secret-auction-race-ai-supremacy-google-microsoft-baidu/ ------ > TOP 2: Introducing the Wikimedia Enterprise API > Score: 47 comments: 12 > Address: https://diff.wikimedia.org/2021/03/16/introducing-the-wikimedia-enterprise-api/ ------ ...
You can clearly see that the above code conforms to the object-oriented style. Because in the code, I define two classes as follows:
-
Post: represents an HN content entry, including fields such as title and link. It is a typical "data class", which is mainly used to connect the "data capture" and "file write" behaviors of the program.
-
HNTopPostsSpider: a crawler class that grabs HN content, including page grabbing, parsing, result writing and other behaviors. It is a class that completes the main work.
Although the script is written in an object-oriented style (in other words, it defines only a few class es), it can meet my needs. However, from a design perspective, it violates the first of the SOLID principles: "Single responsibility principle" (hereinafter referred to as SRP). Let's see why.
The single responsibility principle is the first article in the SOLID principle, which holds that a class should have only one reason to be modified. In other words, each class should assume only one responsibility.
To understand the SRP principle, the most important thing is to understand what the "reason for modification" in the principle represents. Obviously, the software itself is lifeless, and the reason for modification will not come from the software itself. Your program won't suddenly jump up and say, "I think I'm a little slow and need to be optimized.".
All the reasons for modifying the software come from the people related to the software. People are the "culprit" who causes the program to be modified.
For example, in the above crawler script, you can easily find two that need to be modified HNTopPostsSpider Class reasons.
-
Reason 1: the programmer of HN website suddenly updated the page style, and the old xpath parsing algorithm could not parse the new page normally, so fetch() The parsing logic in the method needs to be modified.
-
Reason 2: the user of the program (that is, me) thinks the plain text format is not good-looking and wants to change it to Markdown style, so write_to_file() The output logic in the method needs to be modified.
From these two reasons, HNTopPostsSpider It obviously violates the SRP principle. It undertakes two completely different responsibilities of "grabbing the post list" and "writing the post list to file".
10.2.2 disadvantages of violation of SRP
If a class violates the SRP principle, we will often modify it for different reasons, which may lead to the interaction between different functions. For example, one day I adjusted the page parsing logic in order to adapt to the new style of Hacker News Site, but found that the contents of the output file were also destroyed.
In addition, the more responsibilities a single class undertakes, the more complex and difficult it is to maintain. In the object-oriented field, there is a notorious class: God Class. God Class refers to those classes that contain too many responsibilities, have too much code and can do anything. God Class is a nightmare for all programmers. After encountering God Class, every rational programmer always runs away with his first thought. The farther he runs, the better.
Finally, classes that violate SRP principles are also difficult to reuse. If I want to write another HN related script now, I need to reuse it HNTopPostsSpider Class. I'll find that I can't do it at all, because I have to provide an inexplicable file object to you HNTopPostsSpider Class.
There are a lot of disadvantages of violating the SRP principle, so how to modify the script to make it comply with the SRP principle? There are many methods, among which the most traditional is to divide the large category into small categories.
10.2.3 major categories and minor categories
To make HNTopPostsSpider The responsibility of class becomes more pure. I split the content related to "write file" into a new class: PostsWriter
class PostsWriter:
"""Be responsible for writing the post list to the file"""
def __init__(self, fp: io.TextIOBase, title: str):
self.fp = fp
self.title = title
def write(self, posts: List[Post]):
self.fp.write(f'# {self.title}\n\n')
for i, post in enumerate(posts, 1):
self.fp.write(f'> TOP {i}: {post.title}\n')
self.fp.write(f'> fraction:{post.points} Number of comments:{post.comments_cnt}\n')
self.fp.write(f'> Address:{post.link}\n')
self.fp.write('------\n')Then, for HNTopPostsSpider Class, I just put write_to_file() Method is deleted so that it only remains fetch() method.
class HNTopPostsSpider:
"""Grab Hacker News Top Content entry"""
def __init__(self, limit: int = 5):
...
def fetch(self) -> Iterable[Post]:
...After this modification, hntoppostsspider and PostsWriter Each class conforms to the principle of single responsibility. Only when the parsing logic changes will I modify it HNTopPostsSpider Class, similarly, modify PostsWriter Class has only one reason to adjust the output format.
These two classes can be modified separately without affecting each other.
Finally, since both classes are now responsible for only one thing, I need a new role to concatenate their work, so I implemented a new function get_hn_top_posts():
def get_hn_top_posts(fp: Optional[TextIO] = None):
"""obtain Hacker News of Top Content and write it to a file
:param fp: Files to be written, if not provided, will be printed to standard output
"""
dest_fp = fp or sys.stdout
crawler = HNTopPostsSpider()
writer = PostsWriter(dest_fp, title='Top news on HN')
writer.write(list(crawler.fetch()))New functions by combining HNTopPostsSpider And PostsWriter Class, completed the main work.
Although single responsibility is the design principle of object-oriented domain, it is usually used to describe classes. However, in Python, the scope of application of single responsibility can not be limited to classes -- by defining functions, we can also make the above code comply with the principle of single responsibility.
In the following code, the logic of "write to file" is split into a function, which is specifically responsible for writing the post list to the file:
def write_posts_to_file(posts: List[Post], fp: TextIO, title: str):
"""Be responsible for writing the post list to the file"""
fp.write(f'# {title}\n\n')
for i, post in enumerate(posts, 1):
fp.write(f'> TOP {i}: {post.title}\n')
fp.write(f'> fraction:{post.points} Number of comments:{post.comments_cnt}\n')
fp.write(f'> Address:{post.link}\n')
fp.write('------\n')This function only does one thing, which also conforms to the SRP principle.
Splitting a responsibility into new functions is a solution with Python characteristics. Although it is not so "Object-Oriented", it is very practical. It is even simpler and more efficient than writing classes in many scenarios.
10.3 OCP: open close principle
The second principle of SOLID is "Open – closed principle", which is referred to as OCP principle for short. The OCP principle holds that classes should be Open to extensions and closed to modifications. In other words: you should be able to extend the behavior of a class without modifying it.
This is a seemingly contradictory and confusing design principle. How can you change behavior without modifying the code? Do you use superpowers?
In fact, the OCP principle is not as mysterious as you think. There is an example in line with the OCP principle around you: built-in sorting function sorted(). sorted() It is a built-in function for sorting iteratable objects. Its usage is as follows:
>>> l = [5, 3, 2, 4, 1] >>> sorted(l) [1, 2, 3, 4, 5]
By default, sorted() The sorting strategy is incremental, with the small one in the front and the large one in the back.
Now, if I want to change sorted For example, let it sort by using the result of modulo 3 of all elements. Do I have to modify it sorted() What about the source code of the function? Of course not. I just pass in a custom function when calling the function key Just parameters.
>>> l = [8, 1, 9] >>> sorted(l, key=lambda i: i % 3) [9, 1, 8]
| Sorted according to the result of element modulo 3, 9 divisible by 3 ranks first, followed by 1 and 8 |
From the above example, you can find that sorted() The function is a great example of compliance with OCP principles because it:
-
Open to extensions: you can customize by passing in key Function to extend its behavior
-
Close for modification: you do not need to modify the sort function itself[ 1]
Next, let's go back to my Hacker News crawler script and see how OCP principles affect it.
10.3.1 accept the test of OCP principle
Three days have passed since the last time I modified the Hacker News crawler script with "single responsibility". In these three days, I found that although the script can quickly retrieve the content and is very convenient to use, in most cases, the content retrieved by the script is not what I want to see.
The current version of the script will capture all the popular items regardless of their source, but in fact, I am only interested in the content from specific sites, such as GitHub.
Therefore, I need to make a little modification to the script. I need to modify it HNTopPostsSpider Class to filter the results.
Soon, the code was modified:
from urllib import parse
class HNTopPostsSpider:
...
def fetch(self) -> Iterable[Post]:
"""from HN Grab Top content"""
# ...
counter = 0
for item in items:
if counter >= self.limit:
break
# ...
link = node_title.get('href')
# Focus only on content from github.com
parsed_link = parse.urlparse(link)
if parsed_link.netloc == 'github.com':
counter += 1
yield Post(...)| call urlparse() It will return the resolution result of a URL address - A ParsedResult Object that contains multiple properties, where netloc Representative host address (domain name) |
Next, let me briefly test the modified effect:
$ python news_digester_O_before.py # Top news on HN > TOP 1: Mimalloc – A compact general-purpose allocator > Score: 291 comments: 40 > Address: https://github.com/microsoft/mimalloc ------ ...
It seems that the newly written filter code works, and now only when the content item comes from github.com Is written to the result.
However, as the Greek philosopher Heraclitus said: the only constant in the world is the change itself. Within a few days, my interest changed. I suddenly felt that except GitHub, I came from Bloomberg[ 2 ] So I have to add a new domain name to the script's filtering logic: bloomberg.com.
Then I found that in order to increase bloomberg.com, I have to modify the existing HNTopPostsSpider Class code, adjust that line if parsed_link.netloc == 'github.com' Judgment sentences can achieve my goal.
Remember what the OCP principle says? "Classes should change their behavior by extension rather than modification". According to this definition, the current code obviously violates the OCP principle, because I have to modify the class code to adjust the domain name filtering conditions.
So, how can we make the class conform to the OCP principle so that the behavior can be adjusted without changing the code? The first way is to use inheritance.
10.3.2 code modification through inheritance
Inheritance is an important concept in object-oriented programming. It provides powerful code reuse ability.
There is an important connection between inheritance and OCP principles. Inheritance allows us to extend the behavior of programs by adding new subclasses instead of modifying the original classes, which is just in line with OCP principles. To achieve effective expansion, the key point is to find the unstable and changeable contents in the parent class first. Only by encapsulating these changes into methods (or properties) Subclasses can override this behavior through inheritance.
The topic goes back to my crawler script. In the current demand scenario, HNTopPostsSpider The unstable logic that will change in the class is actually the part of "whether users are interested in items" (who makes me think one idea a day?).
Therefore, I can extract this part of logic and refine it into a new method:
class HNTopPostsSpider:
...
def fetch(self) -> Iterable[Post]:
# ...
for item in items:
# ...
post = Post(...)
# Use the test method to determine whether to return the post
if self.interested_in_post(post):
counter += 1
yield post
def interested_in_post(self, post: Post) -> bool:
"""Determine whether posts should be added to the results"""
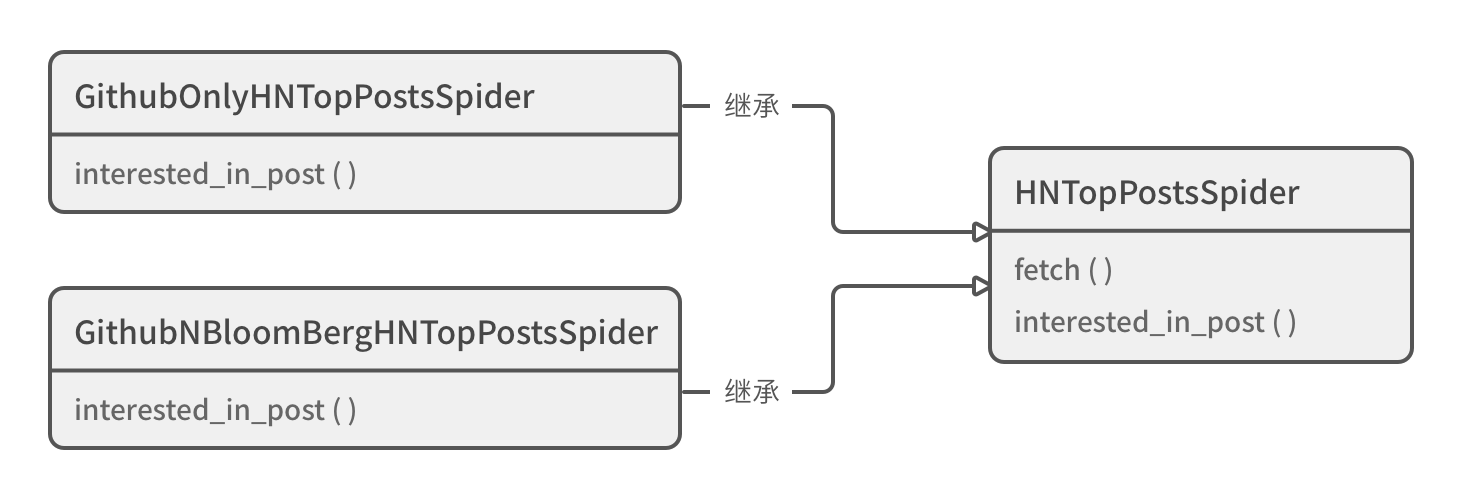
return TrueWith such a structure, if I only care about github.com So I just need to define an inheritance HNTopPostsSpider And then override the parent class interested_in_post() Method.
class GithubOnlyHNTopPostsSpider(HNTopPostsSpider):
"""Only care about from GitHub Content of"""
def interested_in_post(self, post: Post) -> bool:
parsed_link = parse.urlparse(post.link)
return parsed_link.netloc == 'github.com'
def get_hn_top_posts(fp: Optional[TextIO] = None):
# crawler = HNTopPostsSpider()
# Use new subclasses
crawler = GithubOnlyHNTopPostsSpider()
...If one day, my interest changes? It doesn't matter. You don't have to modify the old code, just add a new subclass:
class GithubNBloomBergHNTopPostsSpider(HNTopPostsSpider):
"""Only care about from GitHub/BloomBerg Content of"""
def interested_in_post(self, post: Post) -> bool:
parsed_link = parse.urlparse(post.link)
return parsed_link.netloc in ('github.com', 'bloomberg.com')In this framework, as long as the change of requirements is related to "whether I am interested in the item", I do not need to modify the original HNTopPostsSpider Parent class, I just need to create new subclasses based on it. Through inheritance, I finally realized what the OCP principle says: open to extension and close to change, as shown in Figure 10-2.
10.3.3 using combination and dependency injection
Although inheritance is powerful, it is not the only way to the OCP principle. In addition to inheritance, we can also use another idea: composition. More specifically, we can use dependency injection technology based on composition.
Different from inheritance, dependency injection allows us to inject the changeable part of business logic (often referred to as "algorithm") into the object through initialization parameters when creating the object, and finally use polymorphism to achieve the effect of "extending the class without changing the code".
As previously analyzed, in this script, "item filtering algorithm" is a changeable part of business logic. To implement dependency injection, we need to model the filtering algorithm first.
First, a file named PostFilter Abstract classes for:
from abc import ABC, abstractmethod
class PostFilter(ABC):
"""Abstract class: defines how to filter post results"""
@abstractmethod
def validate(self, post: Post) -> bool:
"""Determine whether the post should be retained"""Then, in order to implement the original logic of the script: no entries are filtered. We have created a default algorithm class that inherits this abstract class: DefaultPostFilter. Its filtering logic is to retain all results.
To implement dependency injection, HNTopPostsSpider Class also needs to make some adjustments. It must receive a file named post_filter Result filter object for:
class DefaultPostFilter(PostFilter):
"""Keep all posts"""
def validate(self, post: Post) -> bool:
return True
class HNTopPostsSpider:
"""Grab Hacker News Top Content entry
:param limit: Limit the number of entries. The default value is 5
:param post_filter: The algorithm for filtering result entries. By default, all items are reserved
"""
items_url = 'https://news.ycombinator.com/'
def __init__(self, limit: int = 5, post_filter: Optional[PostFilter] = None):
self.limit = limit
self.post_filter = post_filter or DefaultPostFilter()
def fetch(self) -> Iterable[Post]:
# ...
counter = 0
for item in items:
# ...
post = Post(...)
# Use the test method to determine whether to return the post
if self.post_filter.validate(post):
counter += 1
yield post| because HNTopPostsSpider The filter that the class depends on is injected through initialization parameters, so this technology is called "dependency injection". |
As the code indicates, when I don't provide post_filter Parameter, HNTopPostsSpider.fetch() All results will be retained without any filtering. If the requirements change, the current filtering logic needs to be modified. Then I just need to create a new one PostFilter Class.
Here are two ways to filter GitHub and Bloomberg respectively PostFilter Class:
class GithubPostFilter(PostFilter):
def validate(self, post: Post) -> bool:
parsed_link = parse.urlparse(post.link)
return parsed_link.netloc == 'github.com'
class GithubNBloomPostFilter(PostFilter):
def validate(self, post: Post) -> bool:
parsed_link = parse.urlparse(post.link)
return parsed_link.netloc in ('github.com', 'bloomberg.com')Creating HNTopPostsSpider Object, I can choose to pass in different filter objects to meet different filtering requirements:
crawler = HNTopPostsSpider() crawler = HNTopPostsSpider(post_filter=GithubPostFilter()) crawler = HNTopPostsSpider(post_filter=GithubNBloomPostFilter())
| Don't filter anything | |
| Filter GitHub site content only | |
| Filter GitHub and Bloomberg sites |
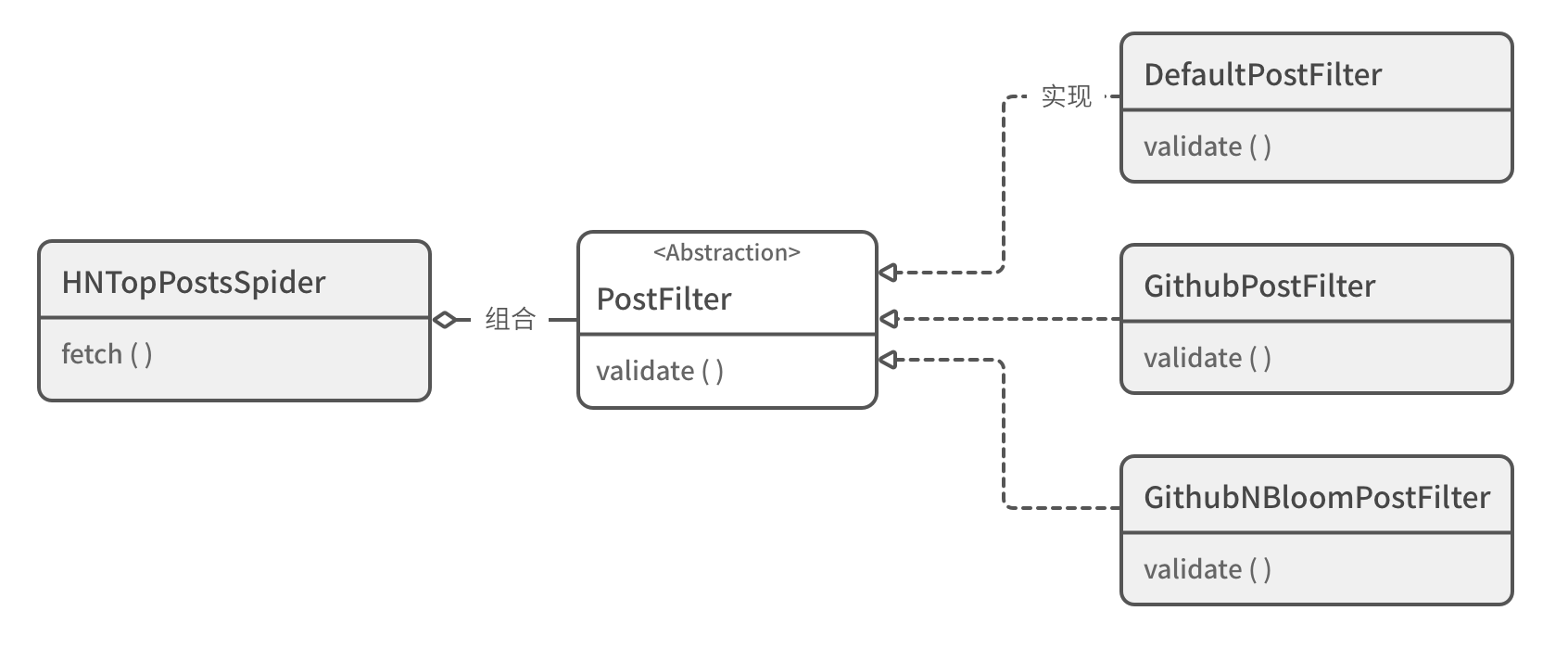
By abstracting and refining the filter algorithm, and combining polymorphism and dependency injection technology, I also make the code comply with the OCP principle.
You can find that the filter algorithm class I write does not share any code in the abstract class, nor does it need to reuse code through inheritance. Therefore, I can not define it at all PostFilter Abstract class, directly write the following filter class.
This will not have any impact on the running effect of the program. Because Python is a "duck type" language, it calls different algorithm classes . validate() (i.e. "polymorphism") will not do any type of inspection before.
But if less PostFilter Abstract classes, when I'm writing HNTopPostsSpider Class __ init__ Way, I can't give it post_filter Added type annotation - post_filter: Optional, because I can't find a specific type at all.
So I have to write an abstract class to meet the needs of type annotation.
This tells us that type annotation is something that makes Python closer to a static language. To enable type annotation, you must find an entity type that can be used as an annotation for anything. Type annotation will force us to express the implicit "interface" and "Protocol" in our brain explicitly.
10.3.4 using data driven
In addition to inheritance and dependency injection, there is another commonly used way to implement OCP principles: data-driven. The core idea of data-driven is to extract the frequently changing parts in the form of data. When the demand changes, only the data can be changed, and the code logic can remain unchanged.
It sounds a bit like data-driven and dependency injection. They both pull the changing things out of the class. The difference between the two is that dependency injection is usually extracted from classes, while data-driven extraction is pure data.
Next, let's try the data-driven scheme in the script.
The first step in transforming to data-driven is to define the data format. In this requirement, the changed part is "the site address I am interested in", so I can simply use a string list filter_by_hosts: [List[str]] To refer to this address.
Here are the modified HNTopPostsSpider Class code:
class HNTopPostsSpider:
"""Grab Hacker News Top Content entry
:param limit: Limit the number of entries. The default value is 5
:param filter_by_hosts: The site list of filtering results. The default is None,Represents no filtering
"""
def __init__(self, limit: int = 5, filter_by_hosts: Optional[List[str]] = None):
self.limit = limit
self.filter_by_hosts = filter_by_hosts
def fetch(self) -> Iterable[Post]:
counter = 0
for item in items:
# ...
post = Post(...)
# Judge whether the link meets the filtering conditions
if self._check_link_from_hosts(post.link):
counter += 1
yield post
def _check_link_from_hosts(self, link: str) -> True:
"""Check whether a link belongs to the defined site"""
if self.filter_by_hosts is None:
return True
parsed_link = parse.urlparse(link)
return parsed_link.netloc in self.filter_by_hostsModified HNTopPostsSpider Class, its caller also needs to adjust. Creating HNTopPostsSpider When creating an instance, I have to pass in the list of sites to be filtered:
hosts = None hosts = ['github.com', 'bloomberg.com'] crawler = HNTopPostsSpider(filter_by_hosts=hosts)
| Don't filter anything | |
| Filter content from github.com and bloomberg.com |
After that, whenever I need to adjust the filtering site, just modify it hosts List without adjustment HNTopPostsSpider Class. This data-driven approach also meets the requirements of OCP principles.
Compared with the previous inheritance and dependency injection, data-driven code is obviously more concise because it does not need to define any additional classes.
But data-driven also has a disadvantage: its customizability is not as good as the other two methods. For example, if I want to filter by "whether the link ends in a string", the current data-driven code can't.
The fundamental reason affecting the customizability of each scheme is that the abstraction level of each scheme is different. For example, in the dependency injection scheme, the abstract content I choose is "item filtering behavior", while in the data-driven scheme, the abstract content is "effective site address of item filtering behavior". Obviously, the latter has a lower level and pays more attention to specific content, so the flexibility is naturally not as flexible as the former.
In daily work, if you want to write code that conforms to OCP principles, there are many different processing methods in addition to inheritance, dependency injection and data-driven demonstrated here. Each method has its own advantages and disadvantages. You need to deeply analyze the specific demand scenarios to determine which method is the most suitable. This is a process that cannot be achieved overnight and requires a lot of practice.
10.4 summary
In this chapter, I describe the first two members of SOLID design principles: single responsibility principle and open close principle through a specific case.
These two principles seem simple, but they actually contain a lot of wisdom extracted from good code, and their scope of application is not limited to object-oriented programming. Once you have a deep understanding of these two principles, you will be surprised to find their shadow in many design patterns and frameworks.
In the next chapter, I will continue to introduce you to the last three SOLID principles. Before that, let's review the main points of the first two principles.
main points
-
Single responsibility principle (SRP)
-
The SRP principle holds that a class should only have one reason to be modified
-
Writing smaller classes is often less likely to violate SRP principles
-
The SRP principle also applies to functions. You can make functions and classes work together
-
-
Open close principle (OCP)
-
The OCP principle holds that classes should be closed to changes and open to extensions
-
By analyzing the requirements and finding the changeable parts of the code, it is the key to make the class conform to the OCP principle
-
Subclass inheritance can make classes conform to OCP principles
-
Through algorithm class and dependency injection, you can also make the class conform to OCP principles
-
Separating data from logic and using data-driven method is also a good way to comply with OCP principles
-