Train yolov4 tiny on Ubuntu 20.04
1, Data download
1.yolov4
Official download: https://github.com/AlexeyAB/darknet
Network disk download link: https://pan.baidu.com/s/1HYiCANZZ4NPYFvMJ-cenFA
Extraction code: 2rh0
2.yolov4-tiny.weights
Official download: https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-tiny.weights
Network disk download link: https://pan.baidu.com/s/1Rui1GNNyXQeEvz-dNdmbQA
Extraction code: jem4
3.yolov4-tiny.conv.29
Official download address: https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-tiny.conv.29
Network disk download link: https://pan.baidu.com/s/15jyob_g98I951bbrBRDyIA
Extraction code: 1ey6
2, Training
1. Configure Makefile file
(1) Modify Makefile file
Modify as follows:
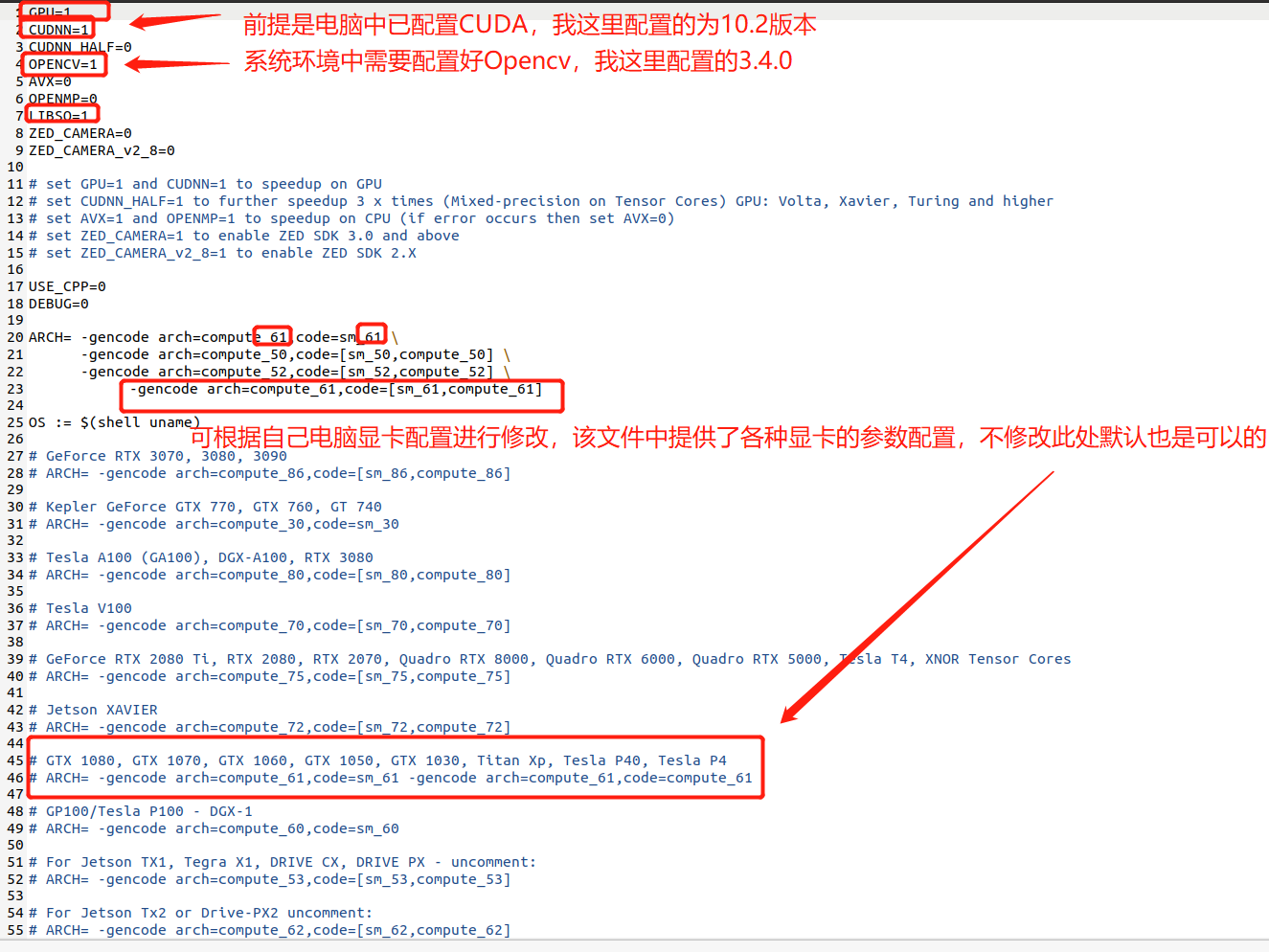
(2) Compile
In the yolov4 directory, open the terminal for compilation
make #The computer CPU is single core perhaps make -j16 #My computer is a multi-core CPU, so I added the parameter - j16 here. Of course, you can try - 4 -j8 according to your computer configuration. Of course, the larger the value after J, the faster the compilation
After running, you can see the generated darknet executable file in the yolov4 directory
2. Dataset training file configuration
(1) Storing data sets
Create the following folder structure under yolov4 directory
---VOCdevkit ---VOC2007 ---Annotations #xml file for own dataset ---ImageSets #Create a new folder to store subsequent txt files ---Main ---JPEGImages #Own data set of picture files, I am jpg format
(2) train, trainval, test and val files are generated in Main
To generate train, trainval, test and val files in the newly created Main folder, first create a python file under the folder voc207 (the file name has no special requirements). The specific code is as follows:
import os
import random
trainval_percent = 0.9 #You can modify it yourself
train_percent = 0.9 #You can modify it yourself
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
Then open the terminal under the VOC2007 folder and run the file:
python3 label.py #label.py is my custom name
Under ImageSets/Main /, you can see the generated four train.txt, trainval.txt, test.txt and val.txt files.
(3) Generate txt files for training in yolov4 directory
Create VOC in yolov4 directory_ Label.py file (or you can find it under scripts, but you need to modify it). The specific code is as follows:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')] #Remove the relevant contents of 2012
classes = ["person"] #Change to the name of your own class
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2007_train.txt 2007_val.txt > train.txt") #Remove the relevant contents of 2012
os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt > train.all.txt") #Remove the relevant contents of 2012
Run the file:
python3 voc_label.py
In the yolov4 directory, you can see that 2007 has been generated_ test.txt,2007_train.txt and 2007_val.txt file.
3. Modify cfg file
Find yolov4-tiny.cfg file in CFG folder and modify it as follows:
[net] # Testing #Test mode, on during test #batch=1 #subdivisions=1 # Training #Training mode, on during training, notes during testing batch=256 # The quantity of each batch. According to the configuration settings, if the memory is small, reduce batch and subdivisions. The larger the batch and subdivisions, the better the effect subdivisions=16 width=416 height=416 channels=3 # The length and width of the input image width height channels are set to a multiple of 32, because the down sampling parameter is 32, the minimum is 320 * 320 and the maximum is 608 * 608 momentum=0.9 # Momentum parameter, influence gradient descent velocity decay=0.0005 # The weight attenuates the regular term to prevent over fitting angle=0 # rotate saturation = 1.5 # Saturation amplification exposure = 1.5 # Exposure hue=.1 # tone learning_rate=0.00261 # Learning rate, weight update speed burn_in=1000 # The number of iterations is less than burn_in, learning rate update; Greater than burn_in, update with policy max_batches = 500200 # Training reaches max_batches stops. The specific value is classes*2000, but the minimum value cannot be less than the number of pictures in your dataset and the minimum value cannot be less than 6000 policy=steps # Learning rate adjustment policy: constant, steps, exp, policy, step, SIG, random steps=400000,450000 # The step value is max_ 80% and 90% of batches scales=.1,.1 # Proportion of change in learning rate [convolutional] batch_normalize=1 filters=32 size=3 stride=2 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=64 size=3 stride=2 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=64 size=3 stride=1 pad=1 activation=leaky [route] layers=-1 groups=2 group_id=1 [convolutional] batch_normalize=1 filters=32 size=3 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=32 size=3 stride=1 pad=1 activation=leaky [route] layers = -1,-2 [convolutional] batch_normalize=1 filters=64 size=1 stride=1 pad=1 activation=leaky [route] layers = -6,-1 [maxpool] size=2 stride=2 [convolutional] batch_normalize=1 filters=128 size=3 stride=1 pad=1 activation=leaky [route] layers=-1 groups=2 group_id=1 [convolutional] batch_normalize=1 filters=64 size=3 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=64 size=3 stride=1 pad=1 activation=leaky [route] layers = -1,-2 [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [route] layers = -6,-1 [maxpool] size=2 stride=2 [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [route] layers=-1 groups=2 group_id=1 [convolutional] batch_normalize=1 filters=128 size=3 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=128 size=3 stride=1 pad=1 activation=leaky [route] layers = -1,-2 [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [route] layers = -6,-1 [maxpool] size=2 stride=2 [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky ################################## [convolutional] batch_normalize=1 filters=256 size=1 stride=1 pad=1 activation=leaky [convolutional] batch_normalize=1 filters=512 size=3 stride=1 pad=1 activation=leaky [convolutional] size=1 stride=1 pad=1 filters=24 # 3*(classes+5) activation=linear [yolo] mask = 3,4,5 anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319 classes=1 # The number of categories is modified to its own category number. I have only one category here, so it is 1 num=6 jitter=.3 scale_x_y = 1.05 cls_normalizer=1.0 iou_normalizer=0.07 iou_loss=ciou ignore_thresh = .7 truth_thresh = 1 random=0 resize=1.5 nms_kind=greedynms beta_nms=0.6 [route] layers = -4 [convolutional] batch_normalize=1 filters=128 size=1 stride=1 pad=1 activation=leaky [upsample] stride=2 [route] layers = -1, 23 [convolutional] batch_normalize=1 filters=256 size=3 stride=1 pad=1 activation=leaky [convolutional] size=1 stride=1 pad=1 **filters=24** # 3*(5+classes) activation=linear [yolo] mask = 1,2,3 anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319 #The initial width and height of the prediction frame, the first is w, the second is h, and the total number is num*2 classes=1 # Number of categories, modified to your own category number num=6 # Number of boundingboxes predicted by each grid jitter=.3 # # Use data jitter to generate more data to suppress overfitting. In YOLOv2, cross, filp, and the angle of the net layer are used. flip is random. Cross is the parameter of jitter. jitter=.2 in tiny-yolo-voc.cfg is to perform cross in 0 ~ 0.2 scale_x_y = 1.05 cls_normalizer=1.0 iou_normalizer=0.07 iou_loss=ciou ignore_thresh = .7 # # The parameter that determines whether the IOU error needs to be calculated. If it is greater than thresh, the IOU error will not be caught in the cost function truth_thresh = 1 random=0 # If it is 1, the image size of each iteration is randomly from 320 to 608, and the step size is 32. If it is 0, the size of each training is consistent with the input size resize=1.5 nms_kind=greedynms beta_nms=0.6
4. Modify voc.names
Modify voc.names under data and fill in according to your actual category name. I have only one person category here. Note that it must be consistent with the category in your label file!
person
5. Modify voc.data
Modify voc.data under cfg. Note: if the following files or folders cannot be found during subsequent training, you can try to use the root path.
classes= 1 # Number of categories train = /home/yourselfpath/darknet-master/2007_train.txt # Training set path valid = /home/yourselfpath/darknet-master/2007_test.txt # Test set path names = data/voc.names backup = backup/ # Model save path
6. Training
Open the terminal input under yolov4: (pay attention to check whether the files in the following instructions are placed in the corresponding positions! The following yolov4.conv.29 has provided the download method at the beginning, remember to put them under yolov4)
./darknet detector train data/voc.data cfg/yolov4-tiny.cfg yolov4.conv.29 -map
Multi GPU training:
./darknet detector train data/voc.data cfg/yolov4-tiny.cfg yolov4.conv.29 -map -gpus 0,1
7. Test
Select the weight file with the most parameters to test
(1) Picture test
./darknet detector test data/voc.data cfg/yolov4-tiny.cfg backup/yolov4-tiny-custom_last.weights data/person.jpg
(2) Video test
./darknet detector demo data/voc.data cfg/yolov4-tiny.cfg backup/yolov4-tiny-custom_last.weights data/1.mp4
(3) Camera test
./darknet detector demo data/voc.data cfg/yolov4-tiny.cfg backup/yolov4-tiny-custom_last.weights -c 0 #If there are multiple cameras, they can be replaced by switching -c the following parameters
3, Reference
1.https://github.com/AlexeyAB/darknet
2.https://blog.csdn.net/u010881576/article/details/107053328