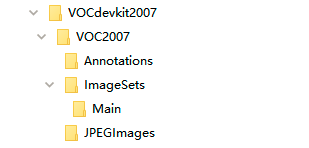
1, Voc207 dataset
the file structure of voc207 dataset is shown in the following figure.
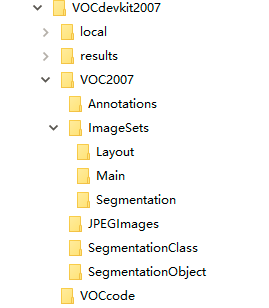
where the folder Annotations stores the xml file of image annotation information, named from 00000 1 xml start; The folder ImageSets stores the txt files of the image divided set, and the txt files of the train, val, trainval and test data sets corresponding to the target detection task are stored in the Main folder; jpg files of all pictures are stored in the JPEGImages folder, named from 00000 1 jpg start; The folders SegmentationClass and SegmentationObject store data information of other tasks.
the contents in the xml file of the annotation information of an image stored in the Annotations folder are as follows.
<annotation> <folder>VOC2007</folder> <!--file name--> <filename>000007.jpg</filename> <!--data sources --> <source> <!--data sources --> <database>The VOC2007 Database</database> <annotation>PASCAL VOC2007</annotation> <!--Source is flickr,A Yahoo image sharing website, here is id,It's of no use to us--> <image>flickr</image> <flickrid>194179466</flickrid> </source> <!--The owner of the picture is useless--> <owner> <flickrid>monsieurrompu</flickrid> <name>Thom Zemanek</name> </owner> <!--Image size,Width, height and length--> <size> <width>500</width> <height>333</height> <depth>3</depth> </size> <!--Whether it is used for segmentation. 0 means it is used for segmentation and 1 means it is not used for segmentation--> <segmented>0</segmented> <!--Here are the objects marked in the image,every last object Contains a standard object--> <object> <!--Object name, shooting angle--> <name>car</name> <pose>Unspecified</pose> <!--Whether it is trimmed. 0 means complete and 1 means incomplete--> <truncated>1</truncated> <!--Is it easy to identify? 0 means easy and 1 means difficult--> <difficult>0</difficult> <!--bounding box Four coordinates of--> <bndbox> <xmin>141</xmin> <ymin>50</ymin> <xmax>500</xmax> <ymax>330</ymax> </bndbox> </object> </annotation>
see → Detailed analysis of VOC2007 dataset.
2, DOTA dataset
official link to DOTA dataset → DOTA dataset link.
Simultaneous interpreting the DOTA data set (A Large-scale Dataset for Object DeTection in Aerial Images) is a large image dataset for target detection in aerial images. It can be used to detect and evaluate objects in aerial images. For the DOTA dataset, it contains 2806 aerial images from different sensors and platforms. The size of each image is about 800. × 800 to 4000 × 4000 pixels and contains objects of various proportions, directions and shapes. These dota images are classified into 15 common object categories by aerial image interpretation experts. The fully annotated dota image contains 188 and 282 instances, each marked by an arbitrary (8-DOF) quadrilateral.
currently, DOTA data sets have three versions:
- DOTA-v1. 0: contains 15 common categories, 2806 images and 188282 instances. DOTA-V1. The proportions of training set, verification set and test set in 0 are 1 / 2, 1 / 6 and 1 / 3 respectively.
plane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, large vehicle, small vehicle, helicopter, roundabout, soccer ball field and swimming pool. - DOTA-v1.5: Used with dota-v1 0 the same image, but very small instances (less than 10 pixels) are also annotated. In addition, a new category "container crane" has been added. It contains a total of 403318 instances. The number of image and dataset segmentation is the same as dota-v1 0 is the same. This version is released for the 2019 DOAI aerial image target detection challenge jointly held with IEEE CVPR 2019.
plane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, large vehicle, small vehicle, helicopter, roundabout, soccer ball field, swimming pool and container crane. - DOTA-v2.0: collect more Google Earth, GF-2 satellite and aerial images. DOTA-v2.0 has 18 common categories, 11268 images and 1793658 instances. With dota-v1 Compared with 5, it further adds new categories of "airport" and "helipad". Dota's 11268 images are divided into training, verification, test verification and test challenge sets.
plane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, large vehicle, small vehicle, helicopter, roundabout, soccer ball field, swimming pool, container crane, airport and helipad.
the file structure of DOTA dataset is shown in the figure below.
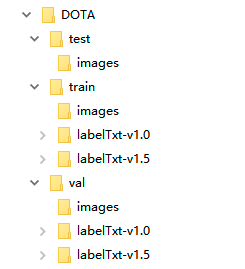
there are three folders: train, Val and test under the DOTA folder of the dataset. There are images and labeltxt-v1 under the folders train and val 0,labelTxt-v1.5 there are three folders. There is only one folder, images, under the folder test.
remote sensing images are stored in the images folder, as shown in the figure below.

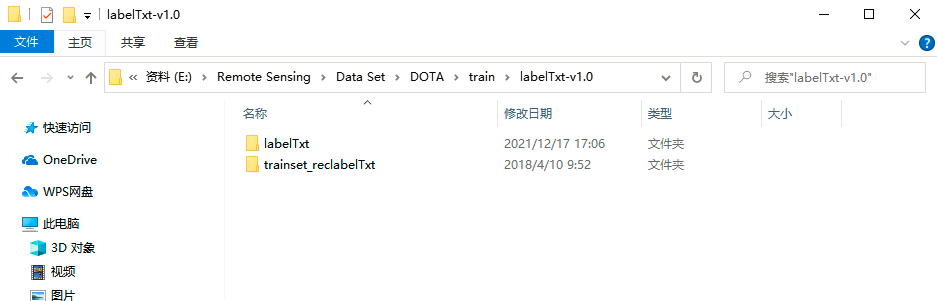
labelTxt-v1. DOTA v1.0 is stored in the 0 folder The label information of version 0 is shown in the figure below, including labeltxt and trainset_ Reclabeltxt two folders. The label information of obb (directional bounding box) is stored in the labeltxt folder, and the label information of hbb (horizontal bounding box) is stored in the trainset_reclabelTxt folder.
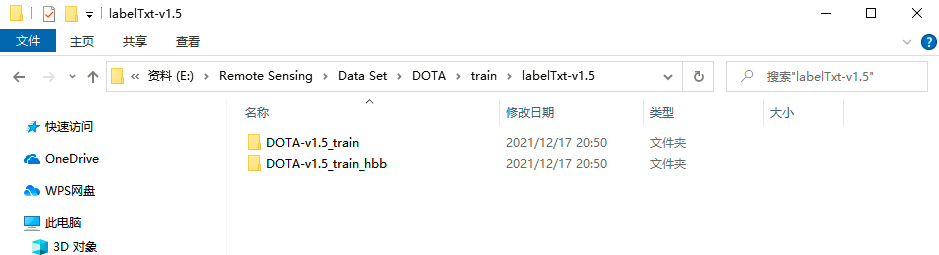
labelTxt-v1.5 folder contains dota v1 5 version of the label information, and labeltxt-v1 0 folder is similar, as shown in the following figure. Under this folder, there are a folder DOTA-v1.5_train for storing obb (directional bounding box) label information and a folder DOTA-v1.5_train_hbb for storing HBB (horizontal bounding box) label information.
3, Convert the format of DOTA dataset to that of voc207 dataset
the following operations are required to convert the format of DOTA dataset to that of voc207 dataset.
- First, the ground truth of pictures in dota dataset can be visualized, and the visualized code is visual_DOTA.py and the results are shown below.
import cv2
import os
import numpy as np
thr=0.95
def custombasename(fullname):
return os.path.basename(os.path.splitext(fullname)[0])
def GetFileFromThisRootDir(dir,ext = None):
allfiles = []
needExtFilter = (ext != None)
for root,dirs,files in os.walk(dir):
for filespath in files:
filepath = os.path.join(root, filespath)
extension = os.path.splitext(filepath)[1][1:]
if needExtFilter and extension in ext:
allfiles.append(filepath)
elif not needExtFilter:
allfiles.append(filepath)
return allfiles
def visualise_gt(label_path, pic_path, newpic_path):
results = GetFileFromThisRootDir(label_path)
for result in results:
f = open(result,'r')
lines = f.readlines()
if len(lines)==0: #If empty
print('The file is empty',result)
continue
boxes = []
for i,line in enumerate(lines):
#score = float(line.strip().split(' ')[8])
#if i in [0,1]: #If you visualize dota-v1 5. The first two lines are unnecessary. Skip and cancel the comment; If you visualize dota-v1 0, the first two lines need to be commented out
# continue
name = result.split('/')[-1]
box=line.strip().split(' ')[0:8]
box = np.array(box,dtype = np.float64)
#if float(score)>thr:
boxes.append(box)
boxes = np.array(boxes,np.float64)
f.close()
filepath=os.path.join(pic_path, name.split('.')[0]+'.png')
im=cv2.imread(filepath)
#print line3
for i in range(boxes.shape[0]):
box =np.array( [[boxes[i][0],boxes[i][1]],[boxes[i][2],boxes[i][3]], \
[boxes[i][4],boxes[i][5]],[boxes[i][6],boxes[i][7]]],np.int32)
box = box.reshape((-1,1,2))
cv2.polylines(im,[box],True,(0,0,255),2)
cv2.imwrite(os.path.join(newpic_path,result.split('/')[-1].split('.')[0]+'.png'),im)
#Here is a score
# x,y,w,h,score=box.split('_')#
# score=float(score)
# cv2.rectangle(im,(int(x),int(y)),(int(x)+int(w),int(y)+int(h)),(0,0,255),1)
# cv2.putText(im,'%3f'%score, (int(x)+int(w),int(y)+int(h)+5),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,255,0),1)
# cv2.imwrite(newpic_path+filename,im)
if __name__ == '__main__':
pic_path = 'E:/Remote Sensing/Data Set/DOTA/train/images/' #Sample image path
label_path = 'E:/Remote Sensing/Data Set/DOTA/train/labelTxt-v1.0/trainset_reclabelTxt/'#Path of DOTA label
newpic_path= 'E:/Remote Sensing/Data Set/DOTA/hbbshow/train/' #Visual save path
if not os.path.isdir(newpic_path):
os.makedirs(newpic_path)
visualise_gt(label_path, pic_path, newpic_path)
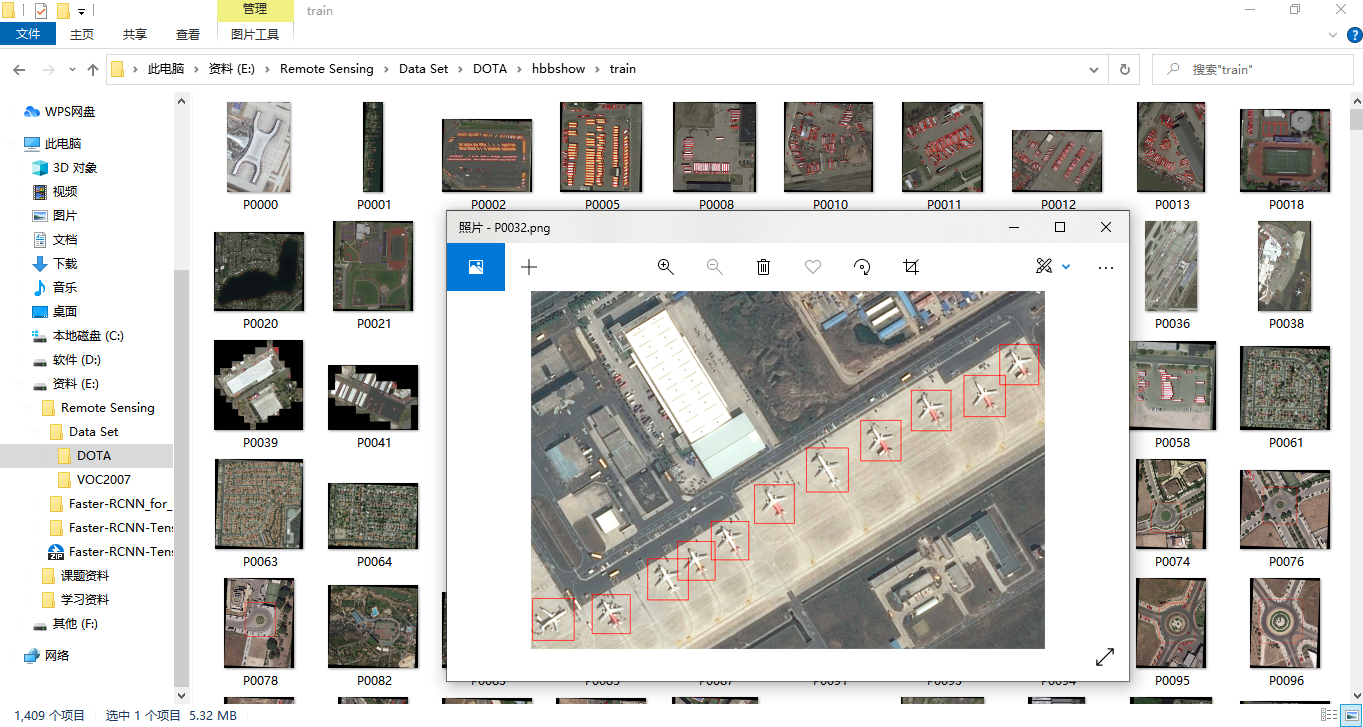
-
Create a DOTA dataset file structure similar to the file structure of voc207 dataset, and only keep the part we need.
-
Because the aspect ratio of some pictures in DOTA dataset is too large to be directly used for subsequent training, it is necessary to cut DOTA dataset. Cut the pictures in the dataset into 600 × \times × 600 fixed size pictures, and generate the xml file of annotation information corresponding to the cut pictures. Cutting code DOTA_VOC.py and the results are shown below.
import os
import imageio
from xml.dom.minidom import Document
import numpy as np
import copy, cv2
def save_to_xml(save_path, im_width, im_height, objects_axis, label_name, name, hbb=True):
im_depth = 0
object_num = len(objects_axis)
doc = Document()
annotation = doc.createElement('annotation')
doc.appendChild(annotation)
folder = doc.createElement('folder')
folder_name = doc.createTextNode('VOC2007')
folder.appendChild(folder_name)
annotation.appendChild(folder)
filename = doc.createElement('filename')
filename_name = doc.createTextNode(name)
filename.appendChild(filename_name)
annotation.appendChild(filename)
source = doc.createElement('source')
annotation.appendChild(source)
database = doc.createElement('database')
database.appendChild(doc.createTextNode('The VOC2007 Database'))
source.appendChild(database)
annotation_s = doc.createElement('annotation')
annotation_s.appendChild(doc.createTextNode('PASCAL VOC2007'))
source.appendChild(annotation_s)
image = doc.createElement('image')
image.appendChild(doc.createTextNode('flickr'))
source.appendChild(image)
flickrid = doc.createElement('flickrid')
flickrid.appendChild(doc.createTextNode('322409915'))
source.appendChild(flickrid)
owner = doc.createElement('owner')
annotation.appendChild(owner)
flickrid_o = doc.createElement('flickrid')
flickrid_o.appendChild(doc.createTextNode('knautia'))
owner.appendChild(flickrid_o)
name_o = doc.createElement('name')
name_o.appendChild(doc.createTextNode('yang'))
owner.appendChild(name_o)
size = doc.createElement('size')
annotation.appendChild(size)
width = doc.createElement('width')
width.appendChild(doc.createTextNode(str(im_width)))
height = doc.createElement('height')
height.appendChild(doc.createTextNode(str(im_height)))
depth = doc.createElement('depth')
depth.appendChild(doc.createTextNode(str(im_depth)))
size.appendChild(width)
size.appendChild(height)
size.appendChild(depth)
segmented = doc.createElement('segmented')
segmented.appendChild(doc.createTextNode('0'))
annotation.appendChild(segmented)
for i in range(object_num):
objects = doc.createElement('object')
annotation.appendChild(objects)
object_name = doc.createElement('name')
object_name.appendChild(doc.createTextNode(label_name[int(objects_axis[i][-1])]))
objects.appendChild(object_name)
pose = doc.createElement('pose')
pose.appendChild(doc.createTextNode('Unspecified'))
objects.appendChild(pose)
truncated = doc.createElement('truncated')
truncated.appendChild(doc.createTextNode('1'))
objects.appendChild(truncated)
difficult = doc.createElement('difficult')
difficult.appendChild(doc.createTextNode('0'))
objects.appendChild(difficult)
bndbox = doc.createElement('bndbox')
objects.appendChild(bndbox)
if hbb:
x0 = doc.createElement('xmin')
x0.appendChild(doc.createTextNode(str((objects_axis[i][0]))))
bndbox.appendChild(x0)
y0 = doc.createElement('ymin')
y0.appendChild(doc.createTextNode(str((objects_axis[i][1]))))
bndbox.appendChild(y0)
x1 = doc.createElement('xmax')
x1.appendChild(doc.createTextNode(str((objects_axis[i][2]))))
bndbox.appendChild(x1)
y1 = doc.createElement('ymax')
y1.appendChild(doc.createTextNode(str((objects_axis[i][5]))))
bndbox.appendChild(y1)
else:
x0 = doc.createElement('x0')
x0.appendChild(doc.createTextNode(str((objects_axis[i][0]))))
bndbox.appendChild(x0)
y0 = doc.createElement('y0')
y0.appendChild(doc.createTextNode(str((objects_axis[i][1]))))
bndbox.appendChild(y0)
x1 = doc.createElement('x1')
x1.appendChild(doc.createTextNode(str((objects_axis[i][2]))))
bndbox.appendChild(x1)
y1 = doc.createElement('y1')
y1.appendChild(doc.createTextNode(str((objects_axis[i][3]))))
bndbox.appendChild(y1)
x2 = doc.createElement('x2')
x2.appendChild(doc.createTextNode(str((objects_axis[i][4]))))
bndbox.appendChild(x2)
y2 = doc.createElement('y2')
y2.appendChild(doc.createTextNode(str((objects_axis[i][5]))))
bndbox.appendChild(y2)
x3 = doc.createElement('x3')
x3.appendChild(doc.createTextNode(str((objects_axis[i][6]))))
bndbox.appendChild(x3)
y3 = doc.createElement('y3')
y3.appendChild(doc.createTextNode(str((objects_axis[i][7]))))
bndbox.appendChild(y3)
f = open(save_path,'w')
f.write(doc.toprettyxml(indent = ''))
f.close()
class_list = ['plane', 'baseball-diamond', 'bridge', 'ground-track-field',
'small-vehicle', 'large-vehicle', 'ship',
'tennis-court', 'basketball-court',
'storage-tank', 'soccer-ball-field',
'roundabout', 'harbor',
'swimming-pool', 'helicopter'] # DOTA v1.0 has 10 categories; DOTA v1.5 has 16 categories, which is better than dota v1 0 has more than one container crane category
def format_label(txt_list):
format_data = []
for i in txt_list[0:]: # Handling dota v1 0 is txt_list[0:]; Handling dota v1 5 to txt_list[2:]
format_data.append(
[int(float(xy)) for xy in i.split(' ')[:8]] + [class_list.index(i.split(' ')[8])]
# {'x0': int(i.split(' ')[0]),
# 'x1': int(i.split(' ')[2]),
# 'x2': int(i.split(' ')[4]),
# 'x3': int(i.split(' ')[6]),
# 'y1': int(i.split(' ')[1]),
# 'y2': int(i.split(' ')[3]),
# 'y3': int(i.split(' ')[5]),
# 'y4': int(i.split(' ')[7]),
# 'class': class_list.index(i.split(' ')[8]) if i.split(' ')[8] in class_list else 0,
# 'difficulty': int(i.split(' ')[9])}
)
if i.split(' ')[8] not in class_list :
print ('warning found a new label :', i.split(' ')[8])
exit()
return np.array(format_data)
def clip_image(file_idx, image, boxes_all, width, height):
# print ('image shape', image.shape)
if len(boxes_all) > 0:
shape = image.shape
for start_h in range(0, shape[0], 256):
for start_w in range(0, shape[1], 256):
boxes = copy.deepcopy(boxes_all)
box = np.zeros_like(boxes_all)
start_h_new = start_h
start_w_new = start_w
if start_h + height > shape[0]:
start_h_new = shape[0] - height
if start_w + width > shape[1]:
start_w_new = shape[1] - width
top_left_row = max(start_h_new, 0)
top_left_col = max(start_w_new, 0)
bottom_right_row = min(start_h + height, shape[0])
bottom_right_col = min(start_w + width, shape[1])
subImage = image[top_left_row:bottom_right_row, top_left_col: bottom_right_col]
box[:, 0] = boxes[:, 0] - top_left_col
box[:, 2] = boxes[:, 2] - top_left_col
box[:, 4] = boxes[:, 4] - top_left_col
box[:, 6] = boxes[:, 6] - top_left_col
box[:, 1] = boxes[:, 1] - top_left_row
box[:, 3] = boxes[:, 3] - top_left_row
box[:, 5] = boxes[:, 5] - top_left_row
box[:, 7] = boxes[:, 7] - top_left_row
box[:, 8] = boxes[:, 8]
center_y = 0.25*(box[:, 1] + box[:, 3] + box[:, 5] + box[:, 7])
center_x = 0.25*(box[:, 0] + box[:, 2] + box[:, 4] + box[:, 6])
# print('center_y', center_y)
# print('center_x', center_x)
# print ('boxes', boxes)
# print ('boxes_all', boxes_all)
# print ('top_left_col', top_left_col, 'top_left_row', top_left_row)
cond1 = np.intersect1d(np.where(center_y[:]>=0 )[0], np.where(center_x[:]>=0 )[0])
cond2 = np.intersect1d(np.where(center_y[:] <= (bottom_right_row - top_left_row))[0],
np.where(center_x[:] <= (bottom_right_col - top_left_col))[0])
idx = np.intersect1d(cond1, cond2)
# idx = np.where(center_y[:]>=0 and center_x[:]>=0 and center_y[:] <= (bottom_right_row - top_left_row) and center_x[:] <= (bottom_right_col - top_left_col))[0]
# save_path, im_width, im_height, objects_axis, label_name
if len(idx) > 0:
name="%s_%04d_%04d.png" % (file_idx, top_left_row, top_left_col)
print(name)
xml = os.path.join(save_dir, 'Annotations', "%s_%04d_%04d.xml" % (file_idx, top_left_row, top_left_col))
save_to_xml(xml, subImage.shape[1], subImage.shape[0], box[idx, :], class_list, str(name))
# print ('save xml : ', xml)
if subImage.shape[0] > 5 and subImage.shape[1] >5:
img = os.path.join(save_dir, 'JPEGImages', "%s_%04d_%04d.png" % (file_idx, top_left_row, top_left_col))
#cv2.imwrite(img, subImage)
cv2.imwrite(img, cv2.cvtColor(subImage, cv2.COLOR_RGB2BGR))
print ('class_list', len(class_list))
raw_images_dir = 'E:/Remote Sensing/Data Set/DOTA/train/images/'
raw_label_dir = 'E:/Remote Sensing/Data Set/DOTA/train/labelTxt-v1.0/trainset_reclabelTxt/'
save_dir = 'E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/'
images = [i for i in os.listdir(raw_images_dir) if 'png' in i]
labels = [i for i in os.listdir(raw_label_dir) if 'txt' in i]
print ('find image', len(images))
print ('find label', len(labels))
min_length = 1e10
max_length = 1
for idx, img in enumerate(images):
print (idx, 'read image', img)
img_data = imageio.imread(os.path.join(raw_images_dir, img))
# if len(img_data.shape) == 2:
# img_data = img_data[:, :, np.newaxis]
# print ('find gray image')
txt_data = open(os.path.join(raw_label_dir, img.replace('png', 'txt')), 'r').readlines()
# print (idx, len(format_label(txt_data)), img_data.shape)
# if max(img_data.shape[:2]) > max_length:
# max_length = max(img_data.shape[:2])
# if min(img_data.shape[:2]) < min_length:
# min_length = min(img_data.shape[:2])
# if idx % 50 ==0:
# print (idx, len(format_label(txt_data)), img_data.shape)
# print (idx, 'min_length', min_length, 'max_length', max_length)
box = format_label(txt_data)
clip_image(img.strip('.png'), img_data, box, 600, 600)
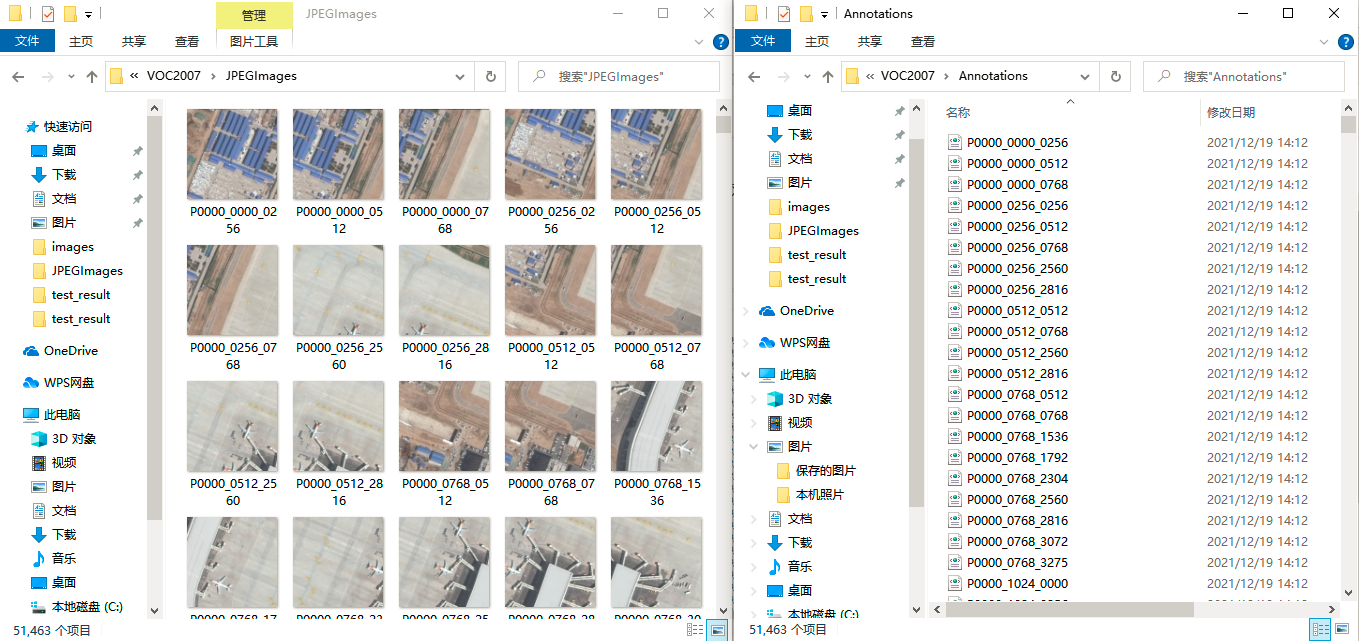
- The obtained after cutting/ Filter the xml files in vocdevkit2007 / voc207 / annotations / folder and remove the unqualified annotation files and/ The corresponding pictures in the VOCdevkit2007/VOC2007/JPEGImages / folder. (Note: there are the following situations for label files that do not meet the requirements: 1. The total number of targets in a label file is 0; 2. The diffcult of all targets in a label file is 1; 3. There is a situation where xmin or ymin is a negative number in a label file.) the code remove.py and the results of removing the file that does not meet the requirements are as follows.
import os
import shutil
import xml.dom.minidom
def custombasename(fullname):
return os.path.basename(os.path.splitext(fullname)[0])
def GetFileFromThisRootDir(dir,ext = None):
allfiles = []
needExtFilter = (ext != None)
for root,dirs,files in os.walk(dir):
for filespath in files:
filepath = os.path.join(root, filespath)
extension = os.path.splitext(filepath)[1][1:]
if needExtFilter and extension in ext:
allfiles.append(filepath)
elif not needExtFilter:
allfiles.append(filepath)
return allfiles
def cleandata(path, img_path, removed_label_path, removed_img_path, ext, label_ext):
name = custombasename(path) #name
if label_ext == '.xml':
DomTree = xml.dom.minidom.parse(path)
annotation = DomTree.documentElement
objectlist = annotation.getElementsByTagName('object')
num = len(objectlist)
difficultlist = annotation.getElementsByTagName('difficult')
xminlist = annotation.getElementsByTagName('xmin')
yminlist = annotation.getElementsByTagName('ymin')
#value = node.getValue
count=0
count1=0
minus=0
for i in range(num):
if int(xminlist[i].firstChild.data)<0 or int(yminlist[i].firstChild.data)<0:
minus+=1
count = count1 + int(difficultlist[i].firstChild.data)
count1 = count
if len(objectlist) == 0 or count == num or minus != 0:
image_path = os.path.join(img_path, name + ext) #Name of sample picture
shutil.move(image_path, removed_img_path) #Move the sample image to blank_img_path
shutil.move(path, removed_label_path) #Move the label of the sample image to blank_label_path
else:
f_in = open(path, 'r') #Open label file
lines = f_in.readlines()
count=0
minus=0
splitlines = [x.strip().split(' ') for x in lines]# Split by space
for i, splitline in enumerate(splitlines):
#if i in [0,1]: #If you visualize dota-v1 5. The first two lines are unnecessary. Skip and cancel the comment; If you visualize dota-v1 0, the first two lines need to be commented out
# continue
difficult = int(splitline[9])
xmin = int(splitline[0])
ymin = int(splitline[1])
if difficult == 0:
count=count+1
if xmin<0 or ymin<0:
minus=minus+1
if len(lines) == 0 or count == 0 or minus != 0: #If it is empty (DOTA v1.0 is len(lines) == 0; DOTA v1.5 is changed to len(lines) == 2) or all target difficult s are all 1
f_in.close()
image_path = os.path.join(img_path, name + ext) #Name of sample picture
shutil.move(image_path, removed_img_path) #Move the sample image to removed_img_path
shutil.move(path, removed_label_path) #Move the label of the sample image to removed_label_path
if __name__ == '__main__':
root = 'E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/'
img_path = os.path.join(root, 'JPEGImages') #Split sample set
label_path = os.path.join(root, 'Annotations') #Split label
ext = '.png' #Picture suffix
label_ext = '.xml'
removed_img_path = os.path.join(root, 'removed_images')
removed_label_path = os.path.join(root, 'removed_annotations')
if not os.path.exists(remove_img_path):
os.makedirs(remove_img_path)
if not os.path.exists(removed_label_path):
os.makedirs(removed_label_path)
label_list = GetFileFromThisRootDir(label_path)
for path in label_list:
cleandata(path, img_path, removed_label_path, removed_img_path, ext, label_ext)
as shown in the figure below/ The VOCdevkit2007/VOC/Annotations / folder stores the remaining xml files after removing the unqualified annotation information files/ In the vocdevkit2007 / voc207 / jpegimages / folder, the remaining png files after removing unqualified pictures are stored/ VOCdevkit2007/VOC2007/removed_ In the annotations / folder, unqualified annotation information files are stored/ VOCdevkit2007/VOC2007/removed_ The images / folder contains pictures that do not meet the requirements.

- The DOTA data set is divided into four files: train, val, trainval and test. Partition code split_data.py and the results are shown below.
import os
import random
trainval_percent = 0.8 # Represents the proportion of training set and verification set (cross verification set) in the total picture
train_percent = 0.75 # Proportion of training set to verification set
xmlfilepath = 'E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/Annotations'
txtsavepath = 'E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent) # Number of cross validation sets in the xml file
tr = int(tv * train_percent) # The number of training sets in the xml file. Note that we previously defined the proportion of training sets in the verification set
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/ImageSets/Main/trainval.txt', 'w')
ftest = open('E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/ImageSets/Main/test.txt', 'w')
ftrain = open('E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/ImageSets/Main/train.txt', 'w')
fval = open('E:/Remote Sensing/Data Set/VOCdevkit2007/VOC2007/ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
print("done!")

- Finally, copy the result folder under the voc207 dataset to the VOC file structure of the new DOTA dataset, which will be used later in training and testing the model.

at this point, we can convert the format of DOTA dataset into the format of voc207 dataset. We get a vocdevkit 2007 folder belonging to dota dataset!
reference article: https://blog.csdn.net/mary_0830/article/details/104263619