1 Overview
This document is mainly composed of
- Two classes, Darknet yolayer,
- Several functions create_modules,get_yolo_layers,load_darknet_weights,save_weights,convert,attempt_download
form
Darknet's constructor first calls parse_model_cfg,create_modules,get_yolo_layers are three functions, so let's start with them and then further analyze them.
2 import library files
There are many important tools in utils, which you should understand later
from utils.google_utils import * from utils.layers import * from utils.parse_config import *
3 parse_model_cfg()
3.1 correction path
This is one in parse_ config. A function of Py, which reads the definition of the model from the cfg file
If there is no suffix, the suffix will be added automatically. If there is no previous path, the path will be added automatically
# Ensure that the path format of the model is correct and will be completed if omitted
if not path.endswith('.cfg'): # add .cfg suffix if omitted
path += '.cfg'
if not os.path.exists(path) and os.path.exists('cfg' + os.sep + path): # add cfg/ prefix if omitted
path = 'cfg' + os.sep + path
3.2 read by line
Read by line,
Remove blank lines, if x
Remove the comment line not x.startswitch ('#'), so the comment needs a separate line
Remove the spaces at both ends. rstrip is the back and lstrip is the front
with open(path, 'r') as f:
lines = f.read().split('\n')
lines = [x for x in lines if x and not x.startswith('#')]
lines = [x.rstrip().lstrip() for x in lines] # get rid of fringe whitespaces
3.3 model definition
Before we see how to handle it, we can first see how the cfg file is written
cfg file, separated by blank lines and comments
[net] # Testing batch=1 subdivisions=1 # Training # batch=64 # subdivisions=2 width=416 height=416 channels=3 momentum=0.9 decay=0.0005 angle=0 saturation = 1.5 exposure = 1.5 hue=.1 learning_rate=0.001 burn_in=1000 max_batches = 500200 policy=steps steps=400000,450000 scales=.1,.1 [convolutional] batch_normalize=1 filters=16 size=3 stride=1 pad=1 activation=leaky
Process by line, read a new module, insert a dictionary at the end of the list and remove []
mdefs = [] # module definitions
for line in lines:
if line.startswith('['): # This marks the start of a new block
mdefs.append({})
# Remove []
mdefs[-1]['type'] = line[1:-1].rstrip()
If it is a convolution block, batch normalize is required, which seems to be very important. Let's take a look later
if mdefs[-1]['type'] == 'convolutional':
# The convolution layer must have batch_normalize? Is this the preemption pit? Prevent forgetting when defining? Because if there is, it will be rewritten.
# pre-populate with zeros (may be overwritten later)
mdefs[-1]['batch_normalize'] = 0
This is to process the contents of each module. Please note that anchor only appears in yolo layer, as shown below
[yolo] mask = 3,4,5 anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319 classes=7 num=6 jitter=.3 ignore_thresh = .7 truth_thresh = 1 random=1
After reading, you need two as a group, so use reshape
else:
key, val = line.split("=")
key = key.rstrip()
if key == 'anchors': # return nparray
mdefs[-1][key] = np.array([float(x) for x in val.split(',')]).reshape((-1, 2)) # np anchors
The rest is to save the corresponding layer with the corresponding type
elif (key in ['from', 'layers', 'mask']) or (key == 'size' and ',' in val): # return array
mdefs[-1][key] = [int(x) for x in val.split(',')]
else:
val = val.strip()
# TODO: .isnumeric() actually fails to get the float case
if val.isnumeric(): # return int or float
mdefs[-1][key] = int(val) if (int(val) - float(val)) == 0 else float(val)
else:
mdefs[-1][key] = val # return string
Check whether there are unsupported modules. If there are, it won't work
# Check all fields are supported
supported = ['type', 'batch_normalize', 'filters', 'size', 'stride', 'pad', 'activation', 'layers', 'groups',
'from', 'mask', 'anchors', 'classes', 'num', 'jitter', 'ignore_thresh', 'truth_thresh', 'random',
'stride_x', 'stride_y', 'weights_type', 'weights_normalization', 'scale_x_y', 'beta_nms', 'nms_kind',
'iou_loss', 'iou_normalizer', 'cls_normalizer', 'iou_thresh', 'probability']
f = [] # fields
Here we start with 1, which is the second in the list, because the first cfg file is net, which is not in supported
for x in mdefs[1:]:
[f.append(k) for k in x if k not in f]
u = [x for x in f if x not in supported] # unsupported fields
assert not any(u), "Unsupported fields %s in %s. See https://github.com/ultralytics/yolov3/issues/631" % (u, path)
return mdefs
4 create_modules()
4.1 basic unit
Using the previous model definition, we use create_modules to build modules_ List, here we need NN ModuleList(),nn.Sequential() has certain understand . First, refer to the above link below. Here's a brief introduction.
- nn.Sequential() is equivalent to defining a small module that executes in sequence
- nn.ModuleList() is equivalent to defining a list to store various small modules. It is similar to list, but it is convenient for parameter filling
Because we study YOLOv3, we study the convolution layer, route, shortcut and YOL;O make a careful analysis of the four
4.2 basic understanding of Yolo network structure
The general network structure is as follows. For details, please refer to this Link 1,this There is some more specific introduction to the residual layer.
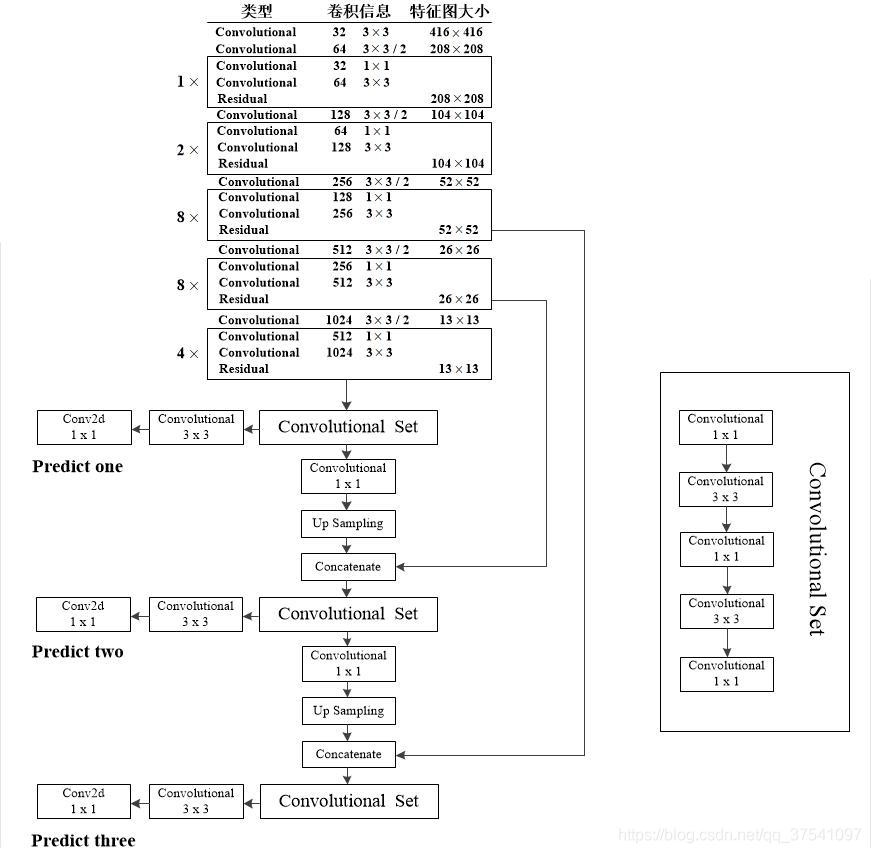
The calculation of related dimensions should be understood later
4.3 convolutional
Convolution is relatively simple. See the code comments for details
if mdef['type'] == 'convolutional':
bn = mdef['batch_normalize']
filters = mdef['filters'] # The number of convolution kernels, how many convolution kernels, the depth of the output is
k = mdef['size'] # kernel size the size of the convolution kernel
stride = mdef['stride'] if 'stride' in mdef else (mdef['stride_y'], mdef['stride_x'])# The step size of stripe or xy is different
if isinstance(k, int): # single-size conv
# Adding a single type of convolution kernel
modules.add_module('Conv2d', nn.Conv2d(in_channels=output_filters[-1],
out_channels=filters,
kernel_size=k,
stride=stride,
padding=k // 2 if mdef['pad'] else 0,
groups=mdef['groups'] if 'groups' in mdef else 1,
bias=not bn))
else: # multiple-size conv
# Add mixed convolution kernel
modules.add_module('MixConv2d', MixConv2d(in_ch=output_filters[-1],
out_ch=filters,
k=k,
stride=stride,
bias=not bn))
The following are some regularization and activation functions. Special attention should be paid here. If there is no batchnormalize in the convolution layer, it means that the next layer is yolo layer, so it is recorded. The index of the corresponding layer is recorded here
# If the convolution layer does not have batchnormalize, it means that the next layer is yolo layer, so it is recorded. Here, the index of the corresponding layer is recorded
if bn:
modules.add_module('BatchNorm2d', nn.BatchNorm2d(filters, momentum=0.03, eps=1E-4))
else:
routs.append(i) # detection output (goes into yolo layer)
# Different types of activation functions
if mdef['activation'] == 'leaky': # activation study https://github.com/ultralytics/yolov3/issues/441
modules.add_module('activation', nn.LeakyReLU(0.1, inplace=True))
elif mdef['activation'] == 'swish':
modules.add_module('activation', Swish())
elif mdef['activation'] == 'mish':
modules.add_module('activation', Mish())
4.4 Upsample
Up sampling is said to enlarge the picture. The specific algorithm is still unknown. At the beginning, it is similar to ONNX_EXPORT is set to false, so as long as you look at the content of else, it is usually doubled.
elif mdef['type'] == 'upsample':
if ONNX_EXPORT: # explicitly state size, avoid scale_factor
g = (yolo_index + 1) * 2 / 32 # gain
modules = nn.Upsample(size=tuple(int(x * g) for x in img_size)) # img_size = (320, 192)
else:
modules = nn.Upsample(scale_factor=mdef['stride'])
4.5 route
There are two types of this module, as follows
[route] layers = -4 [route] layers = -1, 61
- When the layers attribute of this layer has only one layer, it will output the characteristic graph of the value index, for example, - 1, indicating the previous layer
- When there are two parameters, the depth connection results of the corresponding feature maps of the two layers are output [then the size of these feature maps should be the same]
The specific explanations of the code are in the comments
elif mdef['type'] == 'route': # nn.Sequential() placeholder for 'route' layer
layers = mdef['layers']
# The output of each layer is append to output_ In filters, so - 1 takes the last one directly,
# If counting from the beginning, it is + 1 because it starts with 3 channels [this represents input]
filters = sum([output_filters[l + 1 if l > 0 else l] for l in layers])
# Which floor is the record? I don't know how to use it later
routs.extend([i + l if l < 0 else l for l in layers])
# Here is the feature map mosaic
modules = FeatureConcat(layers=layers)
4.6 shortcut layer
The function of this layer is similar to that of the residual network. It is the addition of the feature map, [whether the size of the feature map is guaranteed to be the same]
[shortcut] from=-3 activation=linear
For example, the function of the above module is to add the characteristic diagrams of the previous layer and the first three layers
This activation does not seem to be used in the code
See code comments for specific explanations
elif mdef['type'] == 'shortcut': # nn.Sequential() placeholder for 'shortcut' layer
layers = mdef['from']
# Because you want to add, you can directly use the output size of the previous layer
filters = output_filters[-1]
# Record the two added layers
routs.extend([i + l if l < 0 else l for l in layers])
# Weight blending
modules = WeightedFeatureFusion(layers=layers, weight='weights_type' in mdef)
4.7 YOLO layer
mask selects anchor box es on behalf of the YOLO layer,
anchors, which represents the anchor boxes selected in this experiment
classes stands for several categories
Other parameters are not well understood
[yolo] mask = 3,4,5 anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 classes=80 num=9 jitter=.3 ignore_thresh = .7 truth_thresh = 1 random=1
Construct the YOLO layer and initialize the parameters of the previous convolution layer
elif mdef['type'] == 'yolo':
# yolo layers plus one
yolo_index += 1
stride = [32, 16, 8] # P5, P4, P3 strides
# These need to be in reverse order?
if any(x in cfg for x in ['panet', 'yolov4', 'cd53']): # stride order reversed
stride = list(reversed(stride))
layers = mdef['from'] if 'from' in mdef else []
# Construct yolo module
modules = YOLOLayer(anchors=mdef['anchors'][mdef['mask']], # anchor list
nc=mdef['classes'], # number of classes
img_size=img_size, # (416, 416)
yolo_index=yolo_index, # 0, 1, 2...
layers=layers, # output layers
stride=stride[yolo_index])
# Automatically initialize the bias of the previous volume layer?
# Initialize preceding Conv2d() bias (https://arxiv.org/pdf/1708.02002.pdf section 3.3)
try:
j = layers[yolo_index] if 'from' in mdef else -1
# If previous layer is a dropout layer, get the one before
if module_list[j].__class__.__name__ == 'Dropout':
j -= 1
bias_ = module_list[j][0].bias # shape(255,)
bias = bias_[:modules.no * modules.na].view(modules.na, -1) # shape(3,85)
bias[:, 4] += -4.5 # obj
bias[:, 5:] += math.log(0.6 / (modules.nc - 0.99)) # cls (sigmoid(p) = 1/nc)
module_list[j][0].bias = torch.nn.Parameter(bias_, requires_grad=bias_.requires_grad)
except:
print('WARNING: smart bias initialization failure.')
4.8 record return
Add module to list
# Register module list and number of output filters
# Add the module to the list and record the output dimension at the same time
module_list.append(modules)
output_filters.append(filters)
Record which layers have rout s
routs_binary = [False] * (i + 1)
for i in routs:
routs_binary[i] = True
return module_list, routs_binary
5. YOLOLayer()
In create_module calls the class yolayer. Next, let's study this class
Let's see how to call this class first
Firstly, the anchors, number of types, picture size, yolo and layer of the first layer seem to be empty, and the stripe in v3 is 32, 16 and 8 in turn
modules = YOLOLayer(anchors=mdef['anchors'][mdef['mask']], # anchor list
nc=mdef['classes'], # number of classes
img_size=img_size, # (416, 416)
yolo_index=yolo_index, # 0, 1, 2...
layers=layers, # output layers
stride=stride[yolo_index])
5.1 constructor
See the notes for details
def __init__(self, anchors, nc, img_size, yolo_index, layers, stride):
super(YOLOLayer, self).__init__()
self.anchors = torch.Tensor(anchors) # Convert anchor to tensor
self.index = yolo_index # index of this layer in layers
self.layers = layers # model output layer indices
self.stride = stride # Layer stripe, how to use this stripe is very important
self.nl = len(layers) # number of output layers (3)
self.na = len(anchors) # Number of anchors (3) number of anchors
self.nc = nc # number of classes (80)
# Output dimension = category + 5, where 5 is length, width, x,y and confidence [if you want to modify it, it should be modified here]
self.no = nc + 5 # number of outputs (85)
# Initialize some variables ng, how many grids are there?
self.nx, self.ny, self.ng = 0, 0, 0 # initialize number of x, y gridpoints
# Scale the size of the anchor. The stripe should refer to the size of each grid
self.anchor_vec = self.anchors / self.stride
self.anchor_wh = self.anchor_vec.view(1, self.na, 1, 1, 2)
# This doesn't seem to work
if ONNX_EXPORT:
self.training = False
self.create_grids((img_size[1] // stride, img_size[0] // stride)) # number x, y grid points
5.2 feedforward function
The inputs of the feedforward function are p and out. P is the output of the previous network. It is not clear what out is. It is mainly used in ASFF. Let's ignore it first
There are many if judgments. At present, many of them are false, so we directly focus on the key parts,
- Part of training
Here, the dimension of tensor is reconstructed without too much processing. We need to see how the output and loss function of the previous layer are processed
# p.view(bs, 255, 13, 13) -- > (bs, 3, 13, 13, 85) # (bs, anchors, grid, grid, classes + xywh)
p = p.view(bs, self.na, self.no, self.ny, self.nx).permute(0, 1, 3, 4, 2).contiguous() # prediction
if self.training:
return p
- It's not part of the training. We can see that the training is the direct output of the results, while the test processes the results according to the original text, which involves how the real value of our comparison is.
else: # inference
io = p.clone() # inference output
io[..., :2] = torch.sigmoid(io[..., :2]) + self.grid # xy
io[..., 2:4] = torch.exp(io[..., 2:4]) * self.anchor_wh # wh yolo method
io[..., :4] *= self.stride
torch.sigmoid_(io[..., 4:])
return io.view(bs, -1, self.no), p # view [1, 3, 13, 13, 85] as [1, 507, 85]
6 Darknet class
This class is the main content of this file. Other methods and properties are prepared for him
6.1 constructor
Call the previous method to complete the basic construction. The later version, see and info are not clear
def __init__(self, cfg, img_size=(416, 416), verbose=False):
super(Darknet, self).__init__()
self.module_defs = parse_model_cfg(cfg)# Load model definition
self.module_list, self.routs = create_modules(self.module_defs, img_size, cfg)#Build model list
self.yolo_layers = get_yolo_layers(self) # What layer is yolo on
# torch_utils.initialize_weights(self)
# Darknet Header https://github.com/AlexeyAB/darknet/issues/2914#issuecomment-496675346
self.version = np.array([0, 2, 5], dtype=np.int32) # (int32) version info: major, minor, revision
self.seen = np.array([0], dtype=np.int64) # (int64) number of images seen during training
self.info(verbose) if not ONNX_EXPORT else None # print model description
6.2 forward function
There are two functions, one is forward and the other is forward_once
In the forward function, it is mainly used to judge whether the image enhancement technology is used. If enhanced, the image will be scaled and rotated
def forward(self, x, augment=False, verbose=False):
# Determine whether image enhancement technology is needed
if not augment:
return self.forward_once(x)
else: # Augment images (inference and test only) https://github.com/ultralytics/yolov3/issues/931
# Zoom and rotate the image, and add three transformations to the original image
img_size = x.shape[-2:] # height, width
s = [0.83, 0.67] # scales
y = []
for i, xi in enumerate((x,
torch_utils.scale_img(x.flip(3), s[0], same_shape=False), # flip-lr and scale
torch_utils.scale_img(x, s[1], same_shape=False), # scale
)):
# cv2.imwrite('img%g.jpg' % i, 255 * xi[0].numpy().transpose((1, 2, 0))[:, :, ::-1])
y.append(self.forward_once(xi)[0])
# The output should be processed accordingly to ensure the same
y[1][..., :4] /= s[0] # scale
y[1][..., 0] = img_size[1] - y[1][..., 0] # flip lr
y[2][..., :4] /= s[1] # scale
y = torch.cat(y, 1)
return y, None
Call forward for each picture, whether zoomed or not_ once()
def forward_once(self, x, augment=False, verbose=False):
img_size = x.shape[-2:] # height, width
yolo_out, out = [], []
if verbose:# If it is true, a lot of things will be output. Verbose means verbose
print('0', x.shape)
str = ''
In the test set, some data enhancements will also be made
# Augment images (inference and test only)
# This enhancement seems strange, only for testing?
if augment: # https://github.com/ultralytics/yolov3/issues/931
nb = x.shape[0] # batch size
s = [0.83, 0.67] # scales
x = torch.cat((x,
torch_utils.scale_img(x.flip(3), s[0]), # flip-lr and scale
torch_utils.scale_img(x, s[1]), # scale
), 0)
The main processing part uses verbose to control the output
for i, module in enumerate(self.module_list):
name = module.__class__.__name__
if name in ['WeightedFeatureFusion', 'FeatureConcat']: # sum, concat
if verbose:# If it is true, a lot of things will be output. Verbose means verbose
l = [i - 1] + module.layers # layers
sh = [list(x.shape)] + [list(out[i].shape) for i in module.layers] # shapes
str = ' >> ' + ' + '.join(['layer %g %s' % x for x in zip(l, sh)])
x = module(x, out) # WeightedFeatureFusion(), FeatureConcat()
elif name == 'YOLOLayer':
# When you get to the yolo layer, it will be output. Why do you need to pass an out
yolo_out.append(module(x, out))
else: # run module directly, i.e. mtype = 'convolutional', 'upsample', 'maxpool', 'batchnorm2d' etc.
x = module(x)
# This out is still confused
out.append(x if self.routs[i] else [])
if verbose:# If it is true, a lot of things will be output. Verbose means verbose
print('%g/%g %s -' % (i, len(self.module_list), name), list(x.shape), str)
str = ''
If it is a train, return directly
if self.training: # train
return yolo_out
# This export has not been understood yet
elif ONNX_EXPORT: # export
x = [torch.cat(x, 0) for x in zip(*yolo_out)]
return x[0], torch.cat(x[1:3], 1) # scores, boxes: 3780x80, 3780x4
If it is test, because the output is
return io.view(bs, -1, self.no), p # view [1, 3, 13, 13, 85] as [1, 507, 85]
Therefore, it needs to be processed. First split the output into two parts, splice x, judge whether to process data enhancement, and then output
else: # inference or test
# Split the output into two parts
x, p = zip(*yolo_out) # inference output, training output
# This is to splice the tensor s in x, and 1 represents splicing by column
x = torch.cat(x, 1) # cat yolo outputs
if augment: # de-augment results
x = torch.split(x, nb, dim=0)
x[1][..., :4] /= s[0] # scale
x[1][..., 0] = img_size[1] - x[1][..., 0] # flip lr
x[2][..., :4] /= s[1] # scale
x = torch.cat(x, 1)
return x, p
6.3 fuse and info
- Fuse is mainly used to fuse Conv2d and BatchNorm2d in the model
- info is to output relevant information of the model
7 other functions
- load_darknet_weights loads the weight of the model
- save_weights save weights
- convert weight file format conversion pt and weight
- attempt_download attempted to download a model weight that does not exist